

1. 한 줄 요약
이번 작업은 Power Automate로 구현되어 있던 SharePoint 폴더 생성 자동화 플로우를 리팩토링한 작업이다.
기존 플로우는 특정 업무 유형마다 필요한 폴더를 하나씩 직접 만드는 방식이었다. 그래서 폴더 구조가 조금만 바뀌어도 플로우 내부 액션을 직접 수정해야 했고, 조건문도 길어졌고, 비슷한 액션이 계속 반복됐다.
새 플로우는 이 구조를 바꿨다.
폴더 구조를 플로우에 박아두는 대신, Dataverse의 산출물 마스터 데이터를 읽고, 그 데이터를 기준으로 레벨2/레벨3 폴더 트리를 만든 뒤, 반복문으로 SharePoint 폴더와 Dataverse 산출물 레코드를 생성하는 방식으로 바꿨다.
정리하면 다음과 같다.
| 구분 | 레거시 방식 | 신규 방식 |
|---|---|---|
| 폴더 구조 관리 위치 | Power Automate 액션 안에 하드코딩 | Dataverse 마스터 데이터 기준 |
| 레벨2/레벨3 폴더 생성 | 폴더마다 개별 액션 생성 | 마스터 데이터에서 트리 구성 후 반복 생성 |
| 산출물 폴더 경로 계산 | 긴 if 중첩식으로 분기 |
마스터 데이터의 레벨2/레벨3/산출물명을 조합 |
| 산출물 레코드 생성값 구성 | 문자열 템플릿 + replace() 반복 |
Compose 객체로 payload 구성 |
| 유지보수 방식 | 플로우 수정 필요 | 마스터 데이터 수정 중심 |
| 액션 수 | 184개 | 41개 |
| 성격 | 절차형, 하드코딩 중심 | 데이터 기반, 반복 처리 중심 |
수치로 보면 전체 액션 수는 184개에서 41개로 줄었다.
단순히 보기 편해진 정도가 아니라, 앞으로 폴더 구조가 바뀌었을 때 수정해야 하는 지점 자체가 달라졌다.
2. 이 자동화가 하는 일
이 플로우의 목적은 간단히 말하면 다음과 같다.
업무 프로젝트가 상위 프로젝트와 연결되었을 때, 상위 프로젝트의 SharePoint 폴더 아래에 업무 프로젝트용 기본 폴더 구조를 만들고, 그 폴더 정보와 산출물 정보를 Dataverse 레코드로 남기는 것이다.
조금 더 풀면 다음과 같다.
- Dataverse의
[업무 프로젝트]레코드가 특정 조건을 만족하면 플로우가 실행된다. - 해당 업무 프로젝트에 연결된
[상위 프로젝트]레코드를 조회한다. - 상위 프로젝트에 SharePoint 폴더 정보가 있는지 확인한다.
- 이미 해당 업무 프로젝트에 산출물 레코드가 만들어져 있는지 확인한다.
- 산출물이 아직 없다면, 산출물 마스터 데이터를 기준으로 폴더 구조를 만든다.
- SharePoint에 레벨2 폴더, 레벨3 폴더, 하위 기본 폴더, 산출물 폴더를 생성한다.
- 생성된 폴더의 경로, 폴더 ID, 드라이브 ID 등을 Dataverse 산출물 레코드에 저장한다.
- 필요한 그룹 권한을 부여한다.
이 흐름은 단순한 “폴더 만들기”가 아니다.
SharePoint와 Dataverse가 같이 엮여 있다.
SharePoint에는 실제 폴더가 생기고, Dataverse에는 그 폴더를 업무 시스템에서 다시 참조할 수 있도록 메타데이터가 저장된다. 그래서 둘 중 하나만 성공하고 다른 하나가 실패하면 데이터 정합성이 깨질 수 있다.

3. 왜 리팩토링이 필요했는가
레거시 플로우도 동작 자체는 했다.
문제는 “동작은 하지만 바꾸기 어려운 구조”였다는 점이다.
3.1 폴더 구조가 플로우 내부에 박혀 있었다
레거시 플로우는 레벨2 폴더, 레벨3 폴더, BP/LL 같은 하위 폴더를 각각 개별 액션으로 만들고 있었다.
예를 들어 어떤 업무 유형에는 다음과 같은 폴더들이 필요하다고 하자.
- 레벨2 A
- 레벨2 B
- 레벨2 C
- 레벨3 A-1
- 레벨3 A-2
- 레벨3 B-1
- 레벨3 C-1
- 각 레벨3 아래의 BP 폴더
- 각 레벨3 아래의 LL 폴더
레거시 방식에서는 이 폴더들이 거의 모두 Power Automate 액션으로 직접 존재했다.
즉, 마스터 데이터에 “레벨2 A 아래에 레벨3 A-1이 있다”는 정보가 있어도, 실제 폴더 생성은 플로우 안에서 별도 액션으로 다시 작성되어 있었다.
이러면 문제가 생긴다.
폴더 하나를 추가하려면 마스터 데이터만 고치는 것이 아니라, 플로우도 열어서 액션을 추가해야 한다.
폴더 이름이 바뀌면 플로우 내부 액션명, 경로 생성식, 산출물 경로 분기까지 같이 확인해야 한다.
업무 유형이 늘어나면 분기도 늘어난다.
결국 플로우가 “업무 규칙을 실행하는 도구”가 아니라 “업무 규칙을 직접 들고 있는 거대한 설정 파일”처럼 되어버린다.
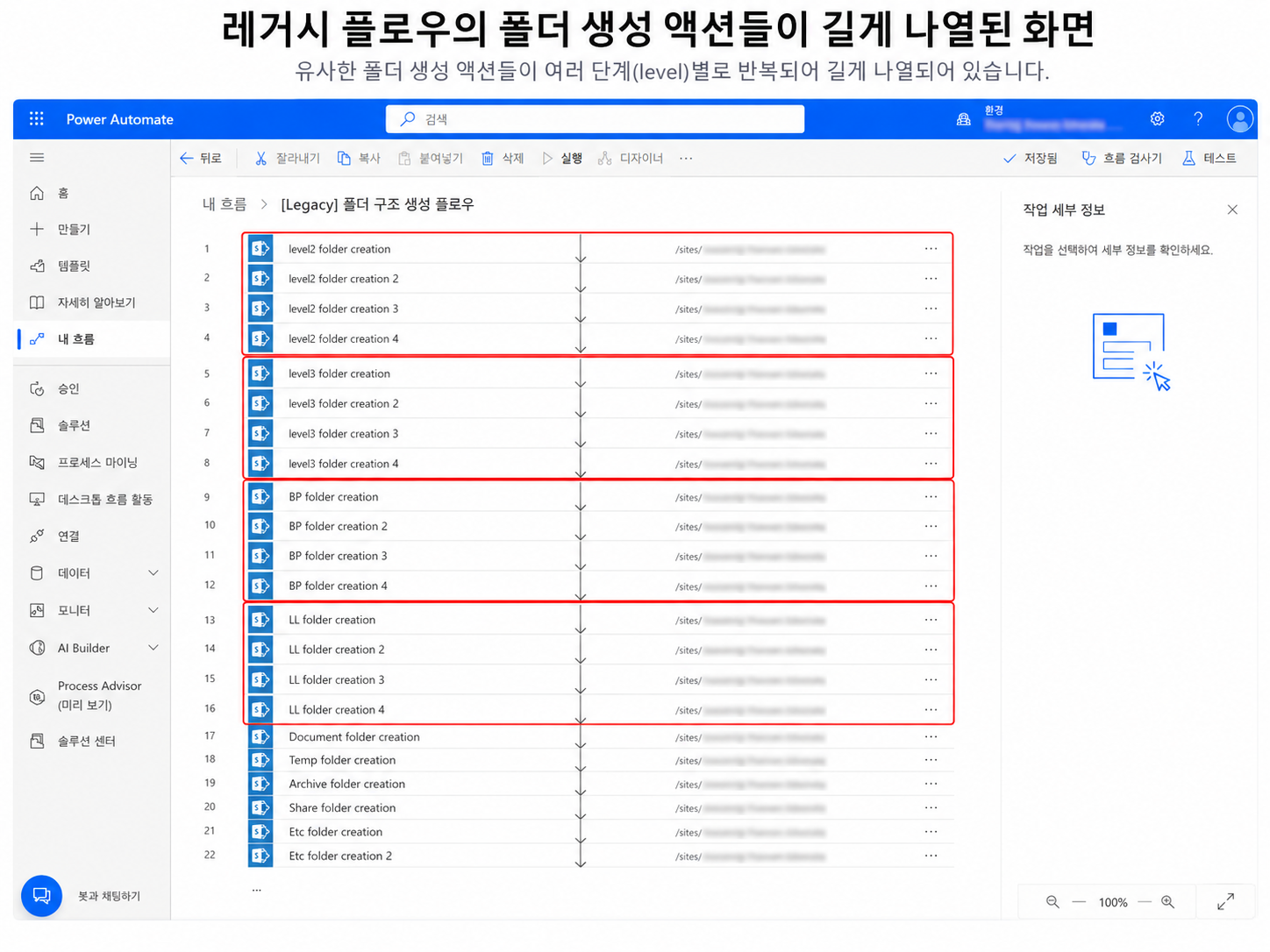
3.2 조건문이 길어질수록 수정 위험이 커졌다
레거시 플로우에서 가장 부담이 컸던 부분은 산출물 폴더가 어느 레벨3 폴더 아래에 생성되어야 하는지 계산하는 부분이었다.
레거시 방식은 대략 이런 형태였다.
if level3Type == 'A' then A 폴더 경로 + 산출물명
else if level3Type == 'B' then B 폴더 경로 + 산출물명
else if level3Type == 'C' then C 폴더 경로 + 산출물명
else if level3Type == 'D' then D 폴더 경로 + 산출물명
...
else 기본 폴더 경로 + 산출물명이 구조는 항목이 적을 때는 버틸 수 있다.
하지만 레벨3 유형이 많아질수록 식이 점점 길어진다.
문제는 길이만이 아니다.
- 특정 레벨3 이름이 바뀌면 조건문 문자열도 바뀌어야 한다.
- 액션명이 바뀌면
outputs('...')참조도 깨질 수 있다. - 괄호가 많아지면 어느 조건의
else인지 확인하기 어렵다. - 한쪽 업무 유형에는 반영했는데 다른 쪽 업무 유형에는 빼먹을 수 있다.
- Power Automate 식 편집기에서는 긴 식을 한눈에 확인하기 어렵다.
그래서 레거시 플로우는 “새 폴더를 하나 추가하는 일”이 “조건문 전체를 다시 읽어야 하는 일”이 되었다.
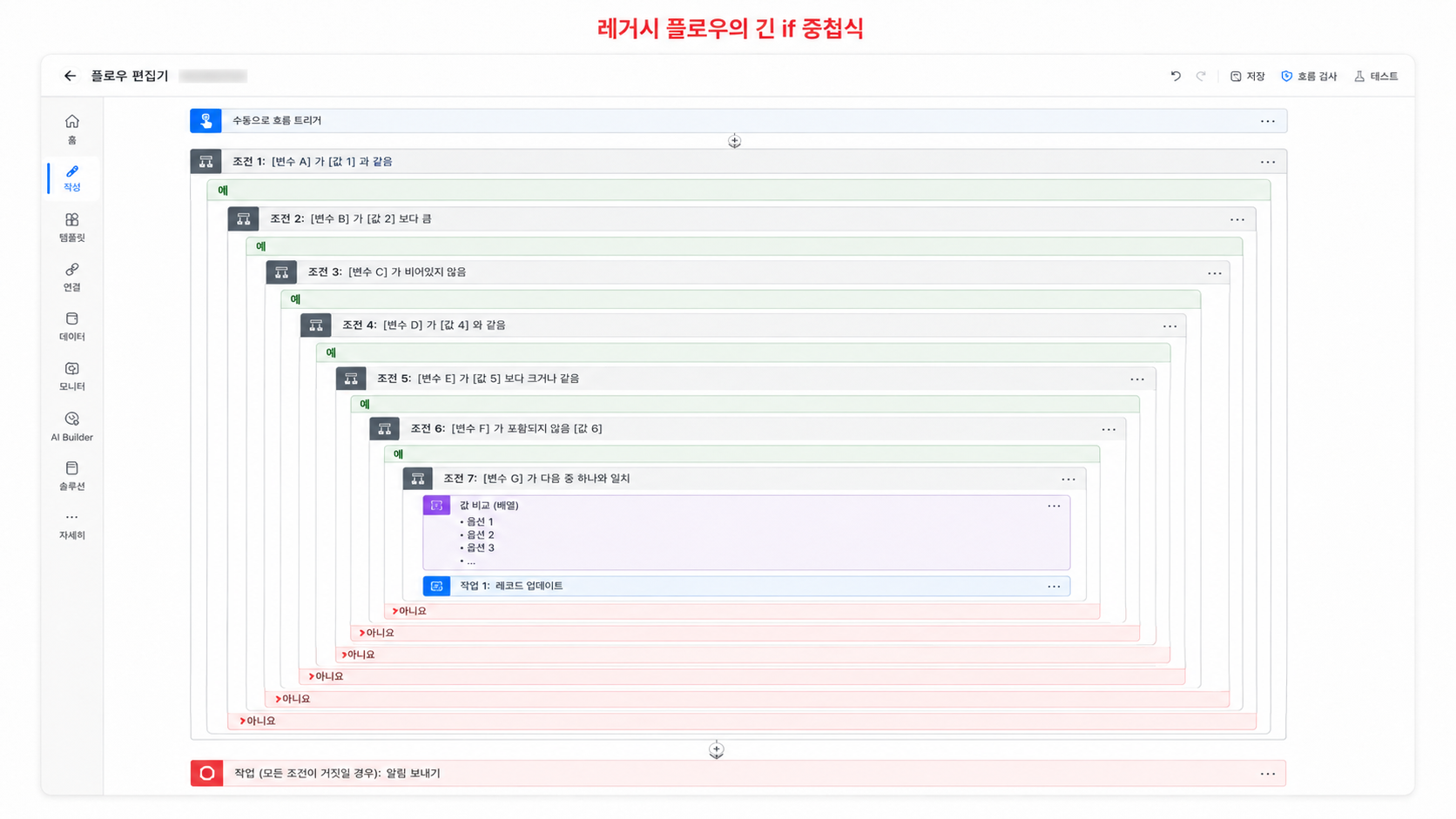
3.3 같은 패턴의 액션이 계속 반복됐다
레거시 플로우에는 비슷한 액션이 매우 많았다.
분석 기준으로 전체 액션 수는 다음과 같았다.
| 액션 타입 | 레거시 | 신규 | 감소량 |
|---|---|---|---|
| 전체 액션 | 184 | 41 | 약 77.7% 감소 |
| OpenApiConnection | 126 | 17 | 약 86.5% 감소 |
| SetVariable | 39 | 2 | 약 94.9% 감소 |
| InitializeVariable | 14 | 5 | 약 64.3% 감소 |
| Foreach | 2 | 4 | 증가 |
| Select / Query / Compose | 거의 없음 | 적극 사용 | 데이터 가공 중심으로 변경 |
여기서 중요한 점은 Foreach가 늘었다는 것이다.
액션 수가 줄었다고 해서 일을 덜 하는 플로우가 된 것은 아니다.
오히려 반복문과 데이터 가공 액션을 사용해서 같은 일을 더 일반화된 방식으로 처리하도록 바뀐 것이다.
레거시에서는 폴더 하나당 액션 하나를 만들었다.
신규에서는 “폴더 목록”을 만들고 그 목록을 순회한다.
이 차이가 유지보수성의 핵심이다.
4. 리팩토링 전 구조
레거시 플로우의 큰 흐름은 다음과 같았다.
[업무 프로젝트] 변경 감지
↓
프로젝트 유형 조회
↓
변수 여러 개 초기화
↓
이미 산출물이 있는지 확인
↓
산출물이 없으면 상위 프로젝트 조회
↓
상위 프로젝트의 SharePoint 폴더 존재 여부 확인
↓
업무 유형 분기
↓
업무 유형별 레벨2 폴더 생성
↓
업무 유형별 레벨3 폴더 생성
↓
각 레벨3 아래 BP/LL 폴더 생성
↓
산출물 마스터 조회
↓
산출물마다 반복
↓
level3Type 변수 설정
↓
name 변수 설정
↓
outputCode 변수 설정
↓
문자열 템플릿 replace
↓
긴 if 식으로 parentFolder 계산
↓
산출물 폴더 생성
↓
Dataverse 산출물 레코드 생성언뜻 보면 순서가 명확해 보이지만, 실제 플로우 화면에서는 액션이 길게 펼쳐져 있어 흐름을 파악하기 어렵다.
특히 문제는 다음 두 구간이었다.
- 업무 유형별 폴더 생성 구간
- 산출물별 parentFolder 계산 구간
4.1 업무 유형별 폴더 생성 구간
레거시 플로우는 업무 유형을 기준으로 분기한 뒤, 각 분기 안에서 레벨2/레벨3 폴더를 직접 생성했다.
예를 들어 업무 유형이 A이면 A 유형에 필요한 폴더 액션들이 줄줄이 있고, 업무 유형이 B이면 B 유형에 필요한 폴더 액션들이 또 별도로 있었다.
이 방식은 처음 만들 때는 직관적이다.
“이 유형이면 이 폴더 만들고, 저 유형이면 저 폴더 만들면 되지”라고 생각하기 쉽다.
하지만 시간이 지나면 문제가 된다.
폴더 구조는 업무 정책이다.
업무 정책은 바뀐다.
그러면 플로우도 계속 바뀌어야 한다.
만약 레벨3 폴더 하나가 추가되면 다음 작업이 필요해진다.
- SharePoint 폴더 생성 액션 추가
- 그 폴더 아래 BP 폴더 생성 액션 추가
- 그 폴더 아래 LL 폴더 생성 액션 추가
- 산출물 폴더 경로 계산식에 새 조건 추가
- 산출물 레코드 생성 시 경로가 맞는지 확인
- 기존 분기와 신규 분기의 차이 확인
- 실행 순서
runAfter확인 - 실패 시 재실행 영향 확인
폴더 하나 추가하는 일치고는 수정 범위가 너무 넓다.
4.2 산출물 레코드 생성 구간
레거시 플로우는 산출물 레코드를 만들기 위해 문자열 템플릿을 먼저 만들고, 그 안의 특정 문자열을 계속 치환하는 방식이었다.
대략 이런 흐름이다.
템플릿 문자열 생성
↓
level2Id 치환
↓
level3Id 치환
↓
folderPath 치환
↓
outputCode 치환
↓
name 치환
↓
mandatory 여부 치환
↓
문자열을 JSON으로 파싱
↓
Dataverse 레코드 생성이 방식은 동작할 수는 있다.
하지만 유지보수 관점에서는 위험한 편이다.
문자열 기반 템플릿은 오타에 취약하다.
치환 순서도 영향을 줄 수 있다.
값 안에 예상하지 못한 문자가 들어오면 JSON 파싱 단계에서 문제가 날 수 있다.
또 실제 레코드에 들어갈 값이 무엇인지 보려면 템플릿과 치환 액션을 모두 따라가야 한다.
신규 플로우에서는 이 부분을 Compose 객체로 바꿨다.
그 결과 “레코드 생성에 필요한 payload가 무엇인지”를 한 액션에서 확인할 수 있게 되었다.
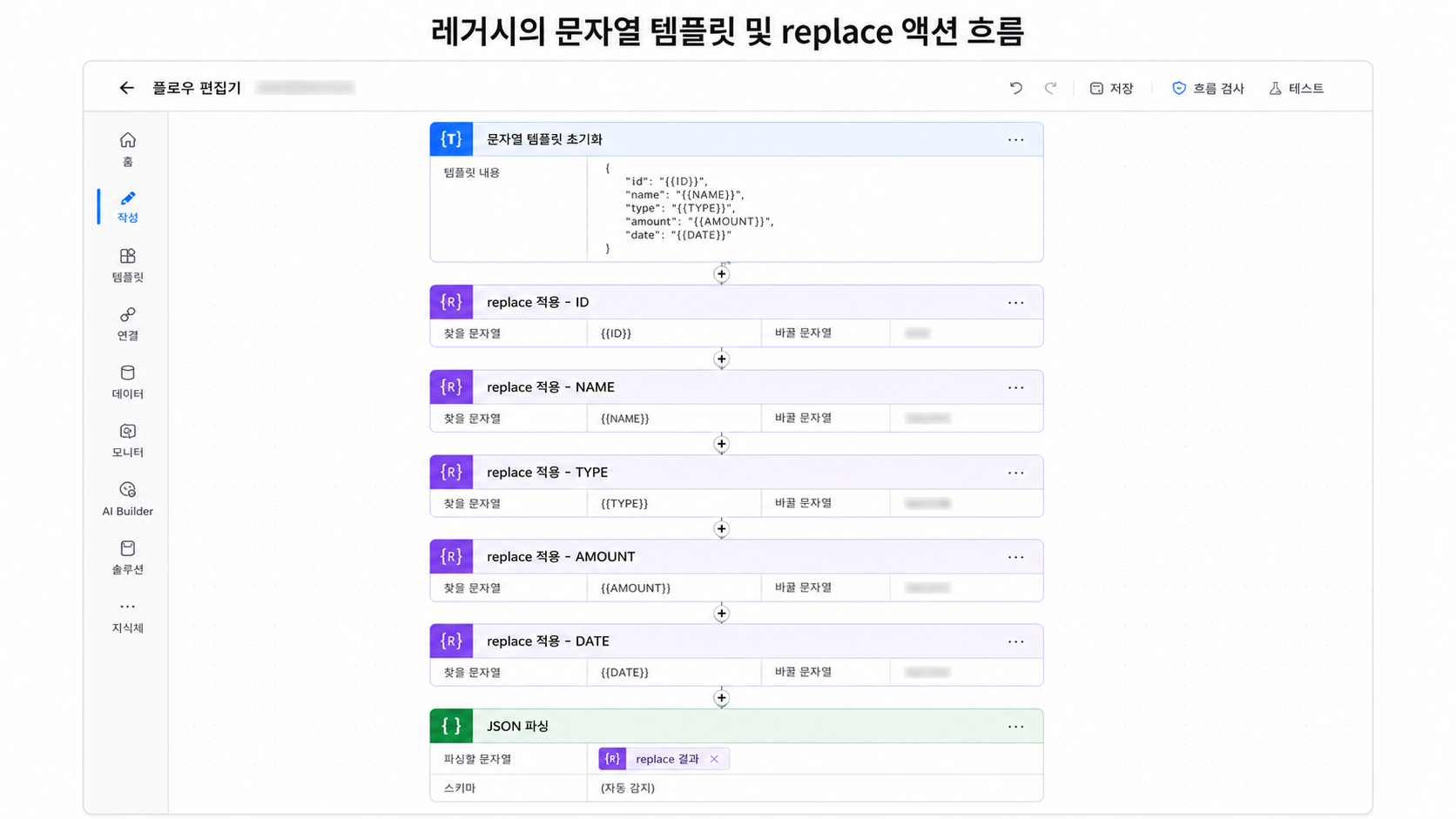
5. 리팩토링 후 구조
신규 플로우의 핵심은 데이터 기반 트리 생성이다.
폴더 구조를 플로우 액션으로 직접 들고 있지 않고, Dataverse 산출물 마스터에서 필요한 정보를 가져온 뒤 다음 형태로 가공한다.
레벨2
├─ 레벨3
│ ├─ BP
│ └─ LL
├─ 레벨3
│ ├─ BP
│ └─ LL
└─ 레벨3
├─ BP
└─ LL그리고 이 트리를 반복문으로 돌면서 SharePoint 폴더를 생성한다.
신규 플로우의 큰 흐름은 다음과 같다.
[업무 프로젝트] 변경 감지
↓
프로젝트 유형 조회
↓
folderPath / sharepoint ID / projectId / projectCode / resultTree 초기화
↓
이미 산출물이 있는지 확인
↓
산출물이 없으면 상위 프로젝트 조회
↓
상위 프로젝트의 SharePoint 폴더 존재 여부 확인
↓
산출물 마스터 전체 조회
↓
현재 프로젝트 유형에 맞는 산출물만 필터링
↓
레벨2/레벨3 페어 추출
↓
중복 레벨2/레벨3 페어 제거
↓
레벨2 목록 추출 및 중복 제거
↓
레벨2별 children 구성
↓
WBS 프로젝트 루트 폴더 생성
↓
레벨2 반복
↓
레벨2 폴더 생성
↓
레벨3 반복
↓
레벨3 폴더 생성
↓
BP 폴더 생성
↓
LL 폴더 생성
↓
산출물 마스터 반복
↓
산출물 폴더 생성
↓
SharePoint 폴더 메타데이터 조회
↓
드라이브 ID 조회
↓
UniqueId 조회
↓
payload Compose
↓
Dataverse 산출물 레코드 생성
↓
그룹 권한 부여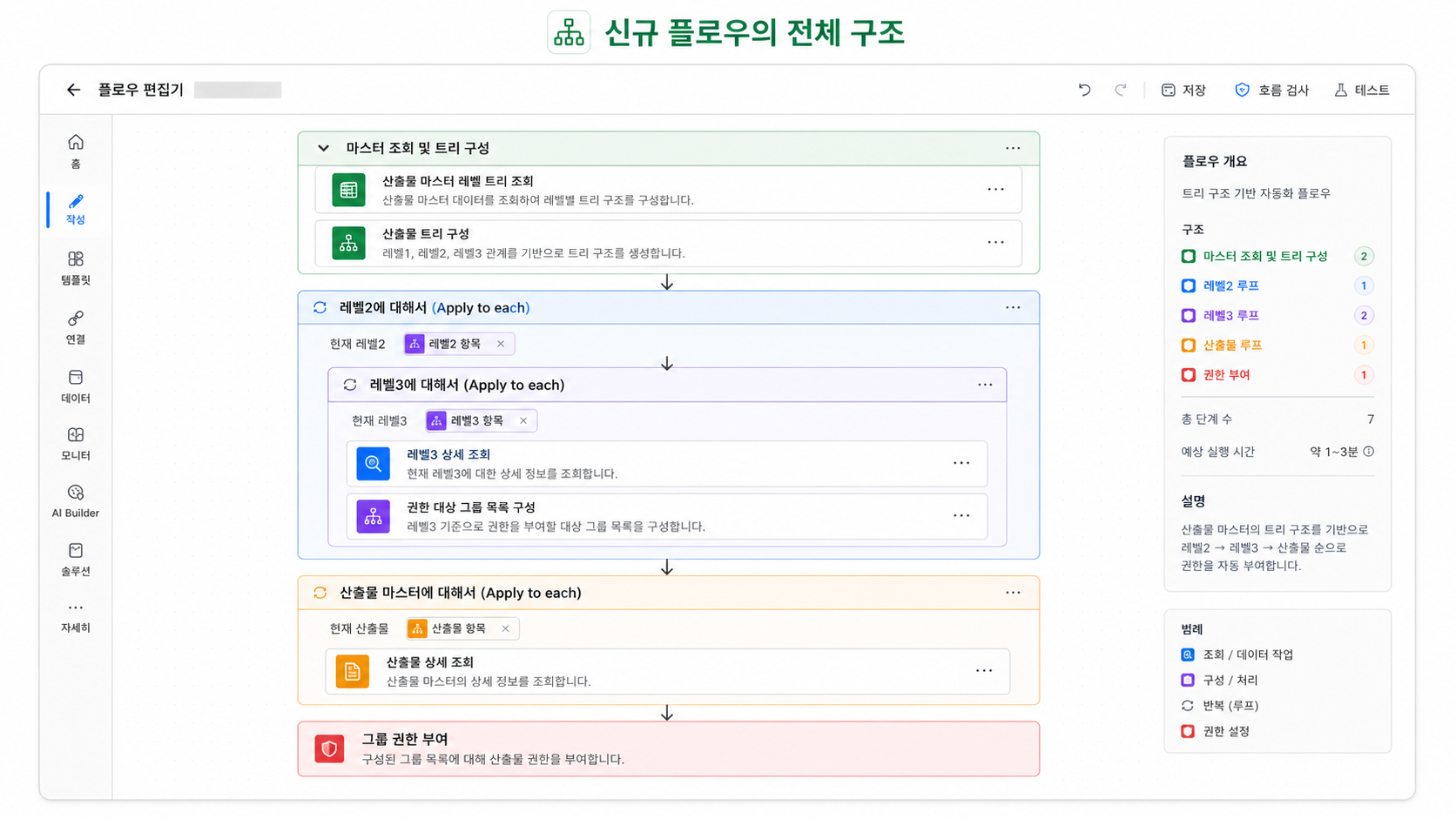
6. 핵심 개선 1: 폴더 구조를 액션이 아니라 데이터로 다루기
신규 플로우에서 가장 중요한 변화는 다음 액션 흐름이다.
산출물 마스터 조회
↓
시공 분류에 맞게 필터링
↓
레벨2와 레벨3 페어링
↓
중복 제거된 레벨 페어
↓
level2만 추출
↓
중복 제거된 level2
↓
각 level2별 children 구성
↓
resultTree에 추가여기서 산출물 마스터는 폴더 구조의 기준 데이터다.
각 산출물 마스터에는 대략 다음 정보가 들어 있다.
| 값 | 의미 |
|---|---|
| 프로젝트 유형 | 이 산출물이 어떤 업무 유형에 해당하는지 |
| 레벨2 ID | 산출물이 속한 상위 폴더 구분 |
| 레벨2 표시명 | SharePoint 폴더명으로 사용할 레벨2 이름 |
| 레벨3 ID | 산출물이 속한 하위 폴더 구분 |
| 레벨3 표시명 | SharePoint 폴더명으로 사용할 레벨3 이름 |
| 산출물명 | 실제 산출물 폴더명 및 레코드명 |
| 산출물 코드 | 업무 시스템에서 식별용으로 사용하는 코드 |
| 필수 여부 | 필수 산출물인지 여부 |
| 영문명 | 필요한 경우 영문 산출물명 |
레거시에서는 이 정보 중 일부를 사용하면서도, 실제 폴더 생성 구조는 플로우에 따로 적혀 있었다.
신규에서는 이 정보를 최대한 그대로 사용한다.
즉, 폴더 구조의 기준을 다음처럼 바꾼 것이다.
기존 기준: 플로우 안에 작성된 폴더 생성 액션 목록
신규 기준: Dataverse 산출물 마스터 데이터이 변화가 중요한 이유는 수정 지점이 줄어들기 때문이다.
예를 들어 레벨3 폴더가 하나 추가된다고 하자.
레거시에서는 플로우를 열어서 액션을 추가해야 한다.
신규에서는 산출물 마스터에 해당 레벨3 값이 들어가 있으면, 플로우는 그 값을 읽고 자동으로 폴더를 만든다.
물론 신규 구조에서도 마스터 데이터의 품질은 중요하다.
마스터 데이터에 잘못된 레벨2/레벨3 매핑이 들어가면 잘못된 폴더가 만들어진다.
하지만 적어도 폴더 구조를 수정하기 위해 자동화 플로우 내부를 계속 뜯어고치는 상황은 줄어든다.

7. 핵심 개선 2: 레벨2/레벨3 페어를 만들고 중복 제거하기
신규 플로우는 산출물 마스터 데이터를 그대로 폴더 생성에 사용하지 않는다.
먼저 레벨2와 레벨3의 관계만 뽑아낸다.
개념적으로는 이런 데이터를 만든다.
| level2Id | level2Name | level3Id | level3Name |
|---|---|---|---|
| L2-001 | 레벨2 A | L3-001 | 레벨3 A-1 |
| L2-001 | 레벨2 A | L3-002 | 레벨3 A-2 |
| L2-002 | 레벨2 B | L3-003 | 레벨3 B-1 |
| L2-002 | 레벨2 B | L3-003 | 레벨3 B-1 |
여기서 마지막 행처럼 같은 레벨2/레벨3 조합이 여러 산출물에서 반복될 수 있다.
산출물은 여러 개여도 폴더는 한 번만 만들면 된다.
그래서 신규 플로우는 union()을 이용해 중복을 제거한다.
Power Automate에서 자주 쓰는 패턴 중 하나다.
union(배열, 배열)같은 배열을 두 번 넣으면 결과적으로 중복이 제거된 배열을 얻을 수 있다.
이 작업을 통해 다음과 같은 결과를 만든다.
| level2Id | level2Name | level3Id | level3Name |
|---|---|---|---|
| L2-001 | 레벨2 A | L3-001 | 레벨3 A-1 |
| L2-001 | 레벨2 A | L3-002 | 레벨3 A-2 |
| L2-002 | 레벨2 B | L3-003 | 레벨3 B-1 |
이제 이 데이터만 있으면 레벨2/레벨3 폴더를 만들 수 있다.

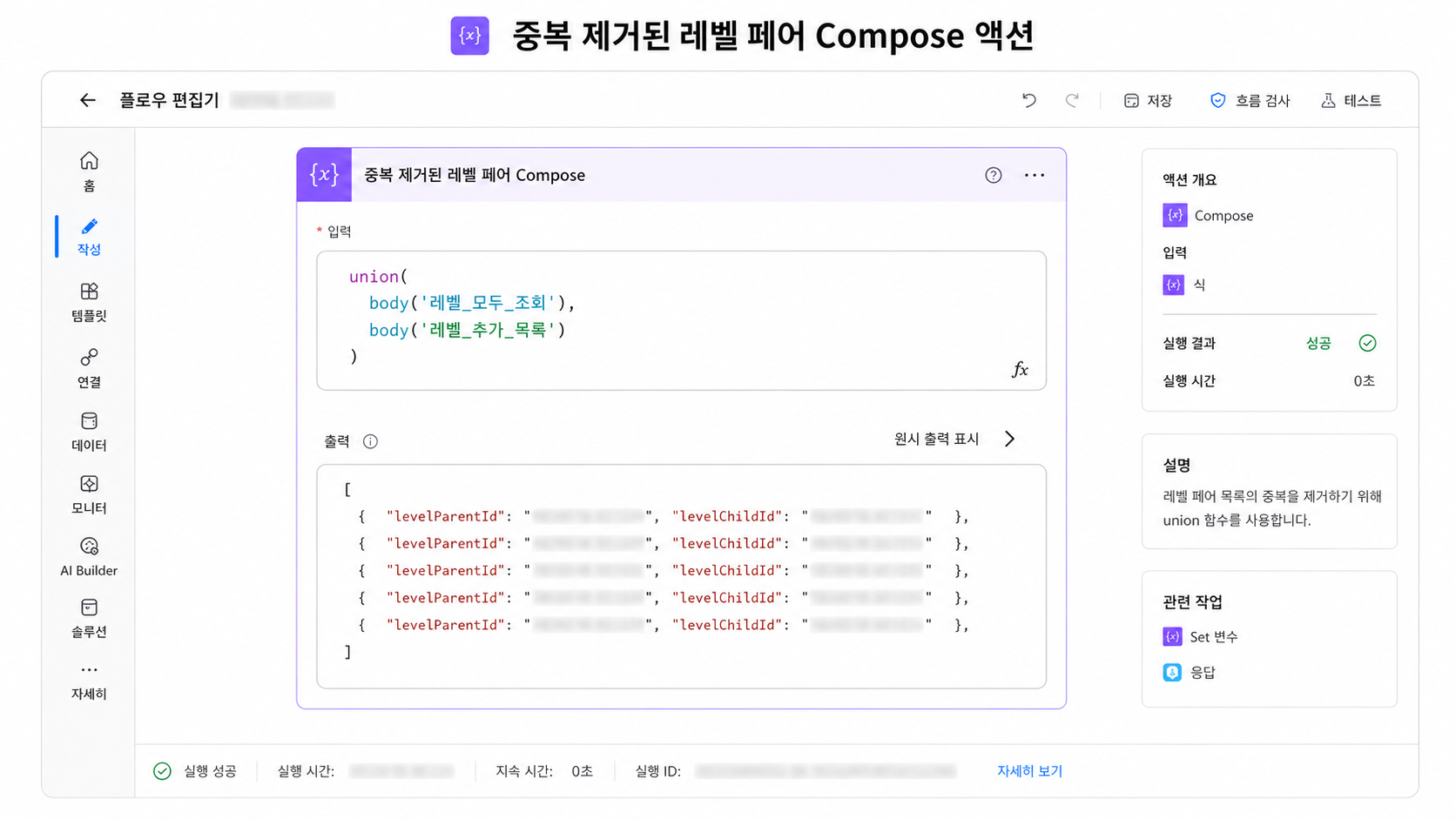
8. 핵심 개선 3: 레벨2 기준으로 children을 구성하기
중복 제거된 레벨2/레벨3 페어만으로도 폴더 생성은 가능하다.
하지만 레벨2 폴더를 만들고, 그 아래에 해당 레벨3 폴더들을 만들려면 데이터를 트리 형태로 바꾸는 것이 좋다.
신규 플로우는 resultTree라는 배열 변수를 사용한다.
개념적으로는 다음과 같은 데이터를 만든다.
[
{
level2Id: "L2-001",
level2Name: "레벨2 A",
children: [
{ level3Id: "L3-001", level3Name: "레벨3 A-1" },
{ level3Id: "L3-002", level3Name: "레벨3 A-2" }
]
},
{
level2Id: "L2-002",
level2Name: "레벨2 B",
children: [
{ level3Id: "L3-003", level3Name: "레벨3 B-1" }
]
}
]이렇게 만들면 이후 폴더 생성 흐름이 매우 자연스러워진다.
for each level2 in resultTree
create level2 folder
for each level3 in level2.children
create level3 folder
create BP folder
create LL folder레거시에서는 레벨2/레벨3가 몇 개인지 플로우가 직접 알고 있었다.
신규에서는 플로우가 개수를 모른다.
대신 resultTree에 들어 있는 만큼 반복한다.
이게 데이터 기반 처리의 핵심이다.
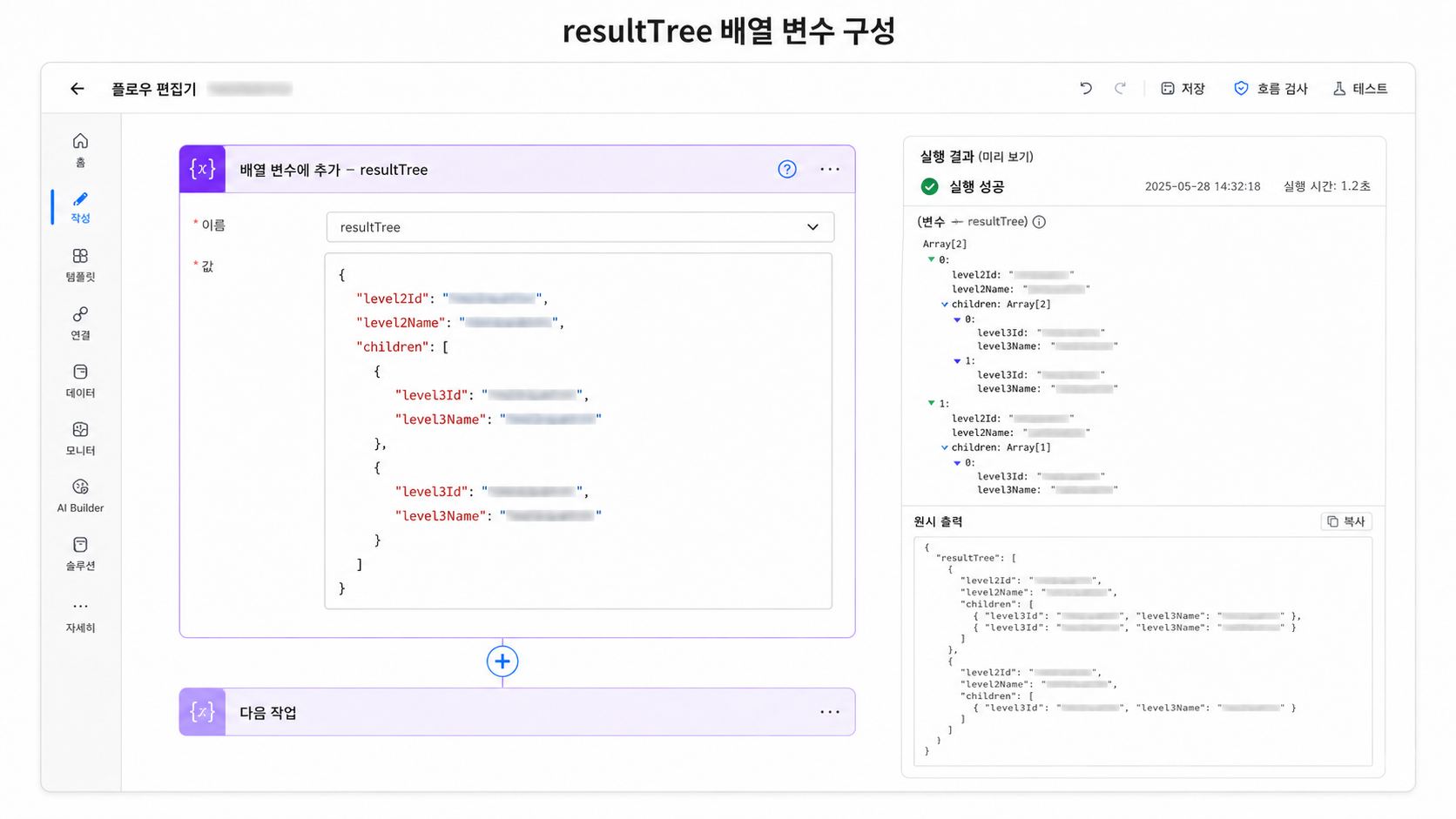
9. 핵심 개선 4: 폴더명에 들어가는 / 처리
SharePoint 폴더 경로를 만들 때 폴더명 안에 /가 들어가면 문제가 생긴다.
/는 경로 구분자로 해석되기 때문이다.
예를 들어 산출물명이 다음과 같다고 하자.
검토/승인 문서이 값을 그대로 경로에 넣으면 SharePoint는 하나의 폴더명이 아니라 다음처럼 해석할 수 있다.
검토
└─ 승인 문서그래서 신규 플로우에서는 레벨2명, 레벨3명, 산출물명에 들어 있는 /를 ·로 치환한다.
검토/승인 문서
↓
검토·승인 문서이 처리는 사소해 보이지만 중요하다.
폴더 경로를 데이터에서 직접 만들기 시작하면, 데이터 안에 들어 있는 문자가 곧 SharePoint 경로가 된다.
그래서 데이터 값이 경로 문법과 충돌하지 않도록 정리해야 한다.
다만 현재 구조에서는 / 치환만 확인했다.
운영 안정성을 더 높이려면 SharePoint에서 제한하는 다른 특수문자도 함께 정리하는 것이 좋다.
예를 들면 다음 문자들이다.
" * : < > ? \ | # % & { }실제 운영에서는 회사 정책이나 SharePoint 제한에 맞춰 “폴더명 정규화 규칙”을 별도로 두는 편이 좋다.

10. 핵심 개선 5: SharePoint 폴더 생성 방식을 REST API 중심으로 변경
레거시 플로우에서는 SharePoint 커넥터의 “새 폴더 만들기” 액션을 많이 사용했다.
신규 플로우에서는 SharePoint HTTP 요청을 사용해 폴더를 생성하는 방식이 중심이 되었다.
개념적으로는 다음과 같은 REST 요청을 사용한다.
POST [SharePoint 사이트]/_api/web/folders
Body: ServerRelativeUrl = 생성할 폴더의 서버 상대 경로이 방식의 장점은 폴더 생성 경로를 명확하게 제어할 수 있다는 점이다.
신규 플로우에서는 다음 폴더들을 REST 방식으로 생성한다.
- WBS 프로젝트 루트 폴더
- 레벨2 폴더
- 레벨3 폴더
- 레벨3 하위 BP 폴더
- 레벨3 하위 LL 폴더
- 산출물 폴더
이때 폴더 경로는 대략 다음 형태로 조합된다.
[상위 프로젝트 SharePoint 폴더]
/ 3. [기본폴더] [프로젝트 코드]
/ [레벨2명]
/ [레벨3명]
/ [산출물명]여기서 [프로젝트 코드], [레벨2명], [레벨3명], [산출물명]은 실제 값 대신 블라인드 처리한 표현이다.
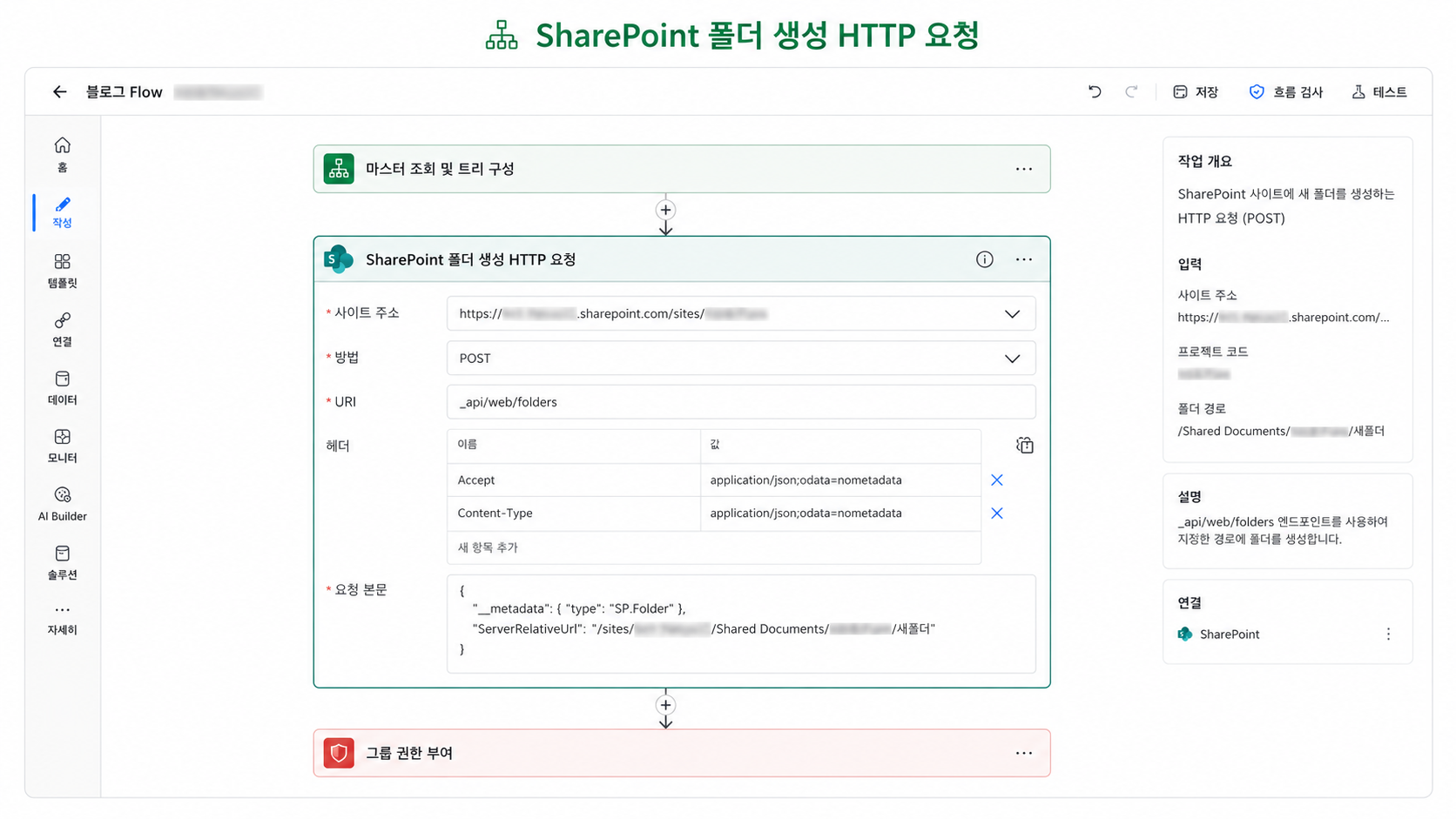
11. 핵심 개선 6: 산출물 레코드 payload를 Compose 객체로 구성
레거시에서는 산출물 레코드 생성값을 문자열 템플릿으로 만들고, 여러 번 replace()를 적용했다.
신규에서는 산출물별로 Compose 액션을 사용해 payload 객체를 만든다.
개념적으로는 다음과 같다.
산출물Payload = {
산출물명: 현재 산출물 마스터의 이름,
산출물코드: 현재 산출물 마스터의 코드,
프로젝트 참조: 현재 업무 프로젝트 ID,
프로젝트 유형 참조: 현재 산출물 마스터의 프로젝트 유형 ID,
레벨2 참조: 현재 산출물 마스터의 레벨2 ID,
레벨3 참조: 현재 산출물 마스터의 레벨3 ID,
폴더경로: 생성된 SharePoint 폴더 경로,
폴더ID: 생성된 SharePoint 폴더의 UniqueId,
드라이브ID: 현재 문서 라이브러리의 DriveId,
필수여부: 현재 산출물 마스터의 필수 여부
}이 방식은 레거시보다 읽기 쉽다.
레코드 생성에 어떤 값이 들어가는지 한 번에 볼 수 있기 때문이다.
또한 문자열 치환 방식보다 구조가 명확하다.
레거시에서는 “문자열을 만들고, 문자열을 바꾸고, 다시 JSON으로 해석”했다.
신규에서는 처음부터 “객체를 만든 뒤, 그 객체의 각 값을 레코드 생성 액션에 넣는 방식”이다.

12. 핵심 개선 7: 폴더 ID와 Drive ID를 더 명확하게 저장
신규 플로우에서는 산출물 폴더 생성 후 다음 정보를 추가로 조회한다.
- 폴더 메타데이터
- 문서 라이브러리 Drive 목록
- 현재 라이브러리의 Drive ID
- 생성된 폴더의 UniqueId
이 과정은 단순히 폴더를 만들고 끝내는 것이 아니라, 이후 업무 시스템에서 해당 폴더를 안정적으로 다시 열 수 있도록 하기 위한 작업이다.
SharePoint 폴더는 경로만으로도 접근할 수 있지만, 경로는 바뀔 수 있다.
사용자가 폴더명을 바꾸거나, 상위 경로가 바뀌거나, 정책상 경로가 조정되면 문자열 경로만으로는 추적이 어려울 수 있다.
반면 ID 계열 값은 시스템 간 연동에서 더 안정적인 참조값으로 사용할 수 있다.
신규 플로우는 산출물 레코드에 다음 성격의 값을 함께 저장하도록 구성되어 있다.
| 저장값 | 의미 |
|---|---|
| 폴더 경로 | 사람이 읽고 확인하기 쉬운 SharePoint 상대 경로 |
| 폴더 UniqueId | SharePoint 폴더를 식별하기 위한 고유값 |
| DriveId | 해당 폴더가 속한 문서 라이브러리/드라이브 식별값 |
이 변경은 나중에 이미지 조회, 문서 링크 생성, Graph API 연동, 폴더 접근 권한 확인 같은 기능을 붙일 때도 유리하다.
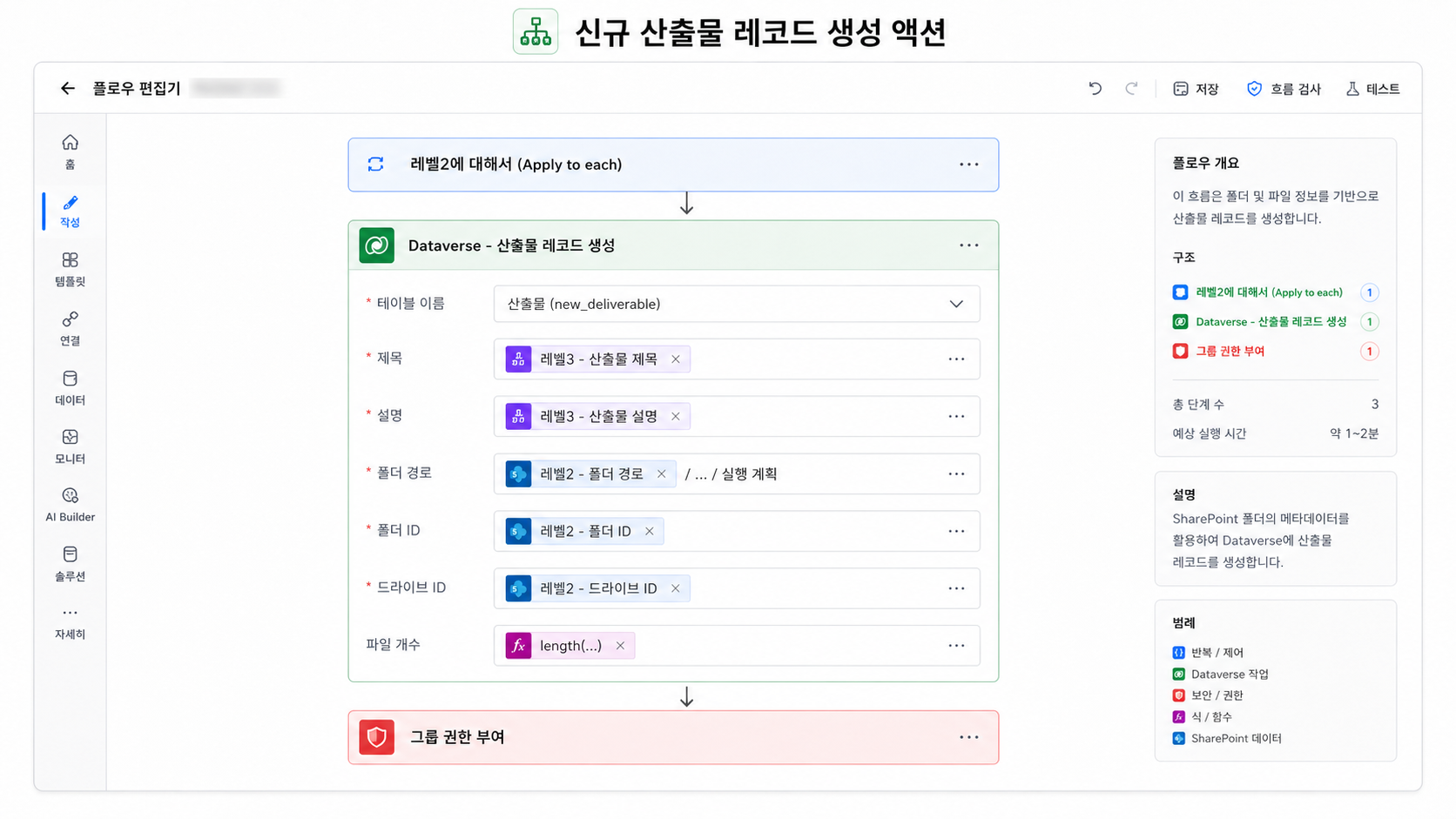
13. 핵심 개선 8: 권한 부여를 루트 폴더 기준으로 정리
레거시 플로우에는 권한 부여 액션도 업무 유형 분기 안에 흩어져 있었다.
신규 플로우에서는 폴더와 산출물 레코드 생성이 끝난 뒤, WBS 프로젝트 루트 폴더에 그룹 권한을 부여하는 형태로 정리되어 있다.
개념적으로는 다음과 같다.
[WBS 프로젝트 루트 폴더]
↓
[권한 대상 그룹]에 접근 권한 부여
↓
하위 폴더에 권한 전파 여부 설정실제 권한 대상 계정이나 그룹 이름은 회사 내부 정보이므로 반드시 블라인드 처리해야 한다.
블로그에 올릴 때는 다음처럼 쓰는 것이 좋다.
peoplePickerInput: [권한 대상 그룹]
roleValue: [권한 수준]권한 부여는 기능상으로는 마지막에 붙어 있는 액션 하나처럼 보이지만, 운영에서는 중요도가 높다.
폴더가 만들어졌는데 권한 부여가 실패하면 사용자는 폴더를 볼 수 없다.
반대로 권한이 너무 넓게 부여되면 보안 문제가 된다.
그래서 권한 부여 액션은 성공 여부를 별도로 모니터링하는 것이 좋다.

14. 리팩토링 결과를 숫자로 보기
이번 리팩토링의 효과를 액션 수 기준으로 보면 꽤 명확하다.
| 항목 | 레거시 | 신규 | 변화 |
|---|---|---|---|
| 전체 액션 수 | 184 | 41 | 143개 감소 |
| OpenApiConnection | 126 | 17 | 109개 감소 |
| SetVariable | 39 | 2 | 37개 감소 |
| InitializeVariable | 14 | 5 | 9개 감소 |
| If | 3 | 2 | 1개 감소 |
| Foreach | 2 | 4 | 2개 증가 |
| Query | 0 | 3 | 데이터 필터링 추가 |
| Select | 0 | 2 | 데이터 매핑 추가 |
| Compose | 0에 가까움 | 5 | 중간 결과 구조화 |
| AppendToArrayVariable | 0 | 1 | 트리 구성 추가 |
액션 수가 줄어든 것보다 더 중요한 것은 액션의 성격이 바뀐 것이다.
레거시의 액션은 대부분 “정해진 폴더 하나를 만든다”에 가까웠다.
신규의 액션은 대부분 “데이터를 조회하고, 가공하고, 반복한다”에 가깝다.
즉, 다음처럼 바뀐 것이다.
하드코딩된 절차 나열
↓
데이터 기반 처리 파이프라인
15. 신규 플로우를 단계별로 자세히 뜯어보기
이제 신규 플로우를 단계별로 더 자세히 정리해보자.
15.1 트리거
신규 플로우는 [업무 프로젝트] 테이블의 행 변경을 기준으로 실행된다.
트리거에는 다음 조건이 들어 있다.
상위 프로젝트 lookup 값이 null이 아닌 경우즉, 업무 프로젝트가 상위 프로젝트에 연결되어 있을 때만 이후 로직을 수행한다.
이 조건이 중요한 이유는 SharePoint 폴더 생성 기준이 상위 프로젝트 폴더이기 때문이다.
상위 프로젝트가 없으면 어느 SharePoint 폴더 아래에 업무 프로젝트 폴더를 만들어야 하는지 알 수 없다.
블로그에서는 실제 트리거 이름과 테이블명은 가려야 한다.
추천 표현은 다음과 같다.
[업무 프로젝트] 레코드가 변경되고, [상위 프로젝트] lookup 값이 존재할 때 실행
15.2 프로젝트 유형 조회
플로우는 먼저 현재 업무 프로젝트의 유형 정보를 조회한다.
이 값은 산출물 마스터를 필터링하는 기준으로 사용된다.
예를 들어 업무 유형이 A이면 A 유형에 필요한 산출물과 폴더만 만들어야 한다.
업무 유형이 B이면 B 유형에 필요한 산출물과 폴더만 만들어야 한다.
레거시에서는 이 유형을 기준으로 큰 분기를 나눴다.
신규에서는 유형을 기준으로 마스터 데이터를 필터링한다.
차이는 크다.
레거시: 유형에 따라 플로우 액션 분기
신규: 유형에 따라 데이터 필터링분기 중심 구조는 유형이 늘어날수록 커진다.
필터링 중심 구조는 유형이 늘어나도 플로우 구조가 크게 바뀌지 않는다.
15.3 기본 변수 초기화
신규 플로우는 다음 성격의 변수를 초기화한다.
| 변수 성격 | 용도 |
|---|---|
| folderPath | 상위 프로젝트의 SharePoint 폴더 상대 경로 저장 |
| sharepoint ID | 상위 프로젝트의 SharePoint 식별값 저장 |
| projectId | 현재 업무 프로젝트 Dataverse ID 저장 |
| projectCode | 업무 프로젝트 폴더명에 사용할 코드 저장 |
| resultTree | 레벨2/레벨3 폴더 구조를 담는 배열 |
레거시에서는 더 많은 문자열 변수와 인덱스 변수를 사용했다.
특히 문자열 템플릿을 단계적으로 바꾸기 위해 idx, idxTemp, name, level3Type, parentFolder, paramForOutput 같은 변수가 많이 필요했다.
신규에서는 payload를 객체로 구성하고, 폴더 구조를 배열로 다루기 때문에 변수 사용이 줄었다.
변수 수가 줄어드는 것은 단순히 화면이 깔끔해지는 것 이상의 의미가 있다.
Power Automate에서 변수는 전역 상태에 가깝다.
여러 액션에서 같은 변수를 수정하면 실행 흐름을 추적하기 어려워진다.
특히 반복문 안에서 변수를 수정하면 병렬 실행 여부에 따라 예상하지 못한 결과가 생길 수도 있다.
그래서 가능한 값은 Compose, Select, Query처럼 입력과 출력이 분명한 액션으로 처리하는 편이 좋다.
15.4 기존 산출물 존재 여부 확인
신규 플로우는 현재 업무 프로젝트에 이미 산출물 레코드가 있는지 먼저 확인한다.
조건은 개념적으로 다음과 같다.
현재 업무 프로젝트 ID로 산출물 레코드를 조회한다.
조회 결과 개수가 0이면 새로 생성한다.이 조건은 중복 생성을 막기 위한 안전장치다.
이미 산출물 레코드가 있는데 플로우가 다시 실행되어 같은 폴더와 같은 산출물 레코드를 만들면 안 된다.
다만 이 방식에는 주의점도 있다.
만약 플로우가 중간에 실패해서 SharePoint 폴더는 일부 생성되었는데 Dataverse 산출물 레코드는 아직 생성되지 않았다면 어떻게 될까?
이 경우 다시 실행했을 때 산출물 레코드 조회 결과는 여전히 0일 수 있다.
그러면 플로우는 다시 폴더 생성을 시도한다.
이미 만들어진 폴더가 있으면 SharePoint 폴더 생성 액션에서 충돌이 날 수 있다.
따라서 운영 안정성을 높이려면 다음 중 하나를 추가하는 것이 좋다.
- 폴더 생성 전 기존 폴더 존재 여부 확인
- 이미 존재하면 생성 대신 기존 폴더 정보 조회
- 409 Conflict 같은 응답을 허용 가능한 상태로 처리
- 중간 실패 복구용 별도 플로우 마련
- Dataverse에 생성 진행 상태를 저장하는 방식 도입
이번 리팩토링의 핵심 범위는 하드코딩 제거와 구조 개선이지만, 운영 관점에서는 이 부분도 반드시 점검해야 한다.

15.5 상위 프로젝트 조회 및 SharePoint 폴더 확인
산출물이 없는 경우에는 상위 프로젝트 레코드를 조회한다.
그리고 상위 프로젝트에 SharePoint 폴더 URL이 있는지 확인한다.
이 조건이 통과되어야 이후 폴더 생성이 가능하다.
상위 프로젝트 폴더가 없으면 하위 업무 프로젝트 폴더를 만들 기준 위치가 없다.
여기서 신규 플로우는 상위 프로젝트의 SharePoint URL에서 불필요한 문자를 제거하고 folderPath 변수에 저장한다.
또 SharePoint 식별값도 별도 변수에 저장한다.
블로그에서는 실제 URL을 절대 노출하면 안 된다.
다음처럼 표현하는 것이 안전하다.
[상위 프로젝트] 레코드의 SharePoint 폴더 경로를 읽어 [folderPath] 변수에 저장한다.
실제 사이트 URL과 문서 라이브러리 경로는 내부 정보이므로 블라인드 처리한다.15.6 산출물 마스터 조회
신규 플로우는 산출물 마스터 테이블을 조회한다.
조회 대상 컬럼은 크게 다음 성격이다.
- 산출물 코드
- 레벨2 lookup
- 레벨3 lookup
- 프로젝트 유형 lookup
이때 모든 마스터 데이터를 가져온 뒤, 현재 프로젝트 유형에 맞는 데이터만 필터링한다.
이 방식은 레거시와 가장 큰 차이를 만든다.
레거시에서는 프로젝트 유형별로 폴더 생성 액션을 나눴다.
신규에서는 프로젝트 유형별로 마스터 데이터를 필터링한다.
즉, 플로우는 더 이상 “A 유형이면 A 폴더 액션 실행, B 유형이면 B 폴더 액션 실행”을 하지 않는다.
대신 이렇게 동작한다.
전체 산출물 마스터를 가져온다.
현재 프로젝트 유형에 해당하는 행만 남긴다.
남은 행에서 레벨2/레벨3/산출물 정보를 읽는다.이 구조에서는 새 업무 유형이 추가되더라도, 마스터 데이터가 올바르게 들어가 있다면 플로우 구조 자체는 크게 바꾸지 않아도 된다.
단, 현재 구조에서는 프로젝트 유형의 표시명을 기준으로 필터링하는 부분이 있다.
표시명은 사용자가 바꿀 수 있고, 언어 설정이나 명칭 변경에 영향을 받을 수 있다.
더 안정적으로 만들려면 가능하면 표시명보다 ID 기준으로 비교하는 편이 좋다.
예를 들면 개념적으로 다음이 더 안전하다.
표시명 비교: 현재 유형 이름 == 마스터의 유형 이름
ID 비교: 현재 유형 ID == 마스터의 유형 ID표시명 비교는 사람이 보기에는 편하지만, 운영 자동화에서는 ID 비교가 더 견고하다.

15.7 레벨2/레벨3 트리 생성
필터링된 산출물 마스터에서 레벨2/레벨3 관계를 추출한다.
이 단계의 목적은 산출물 개수와 상관없이 실제로 만들어야 하는 폴더 구조만 얻는 것이다.
예를 들어 산출물 10개가 같은 레벨3 폴더 아래에 있다면, 레벨3 폴더는 한 번만 만들면 된다.
그래서 다음 흐름을 거친다.
산출물 마스터 목록
↓
레벨2/레벨3 페어만 추출
↓
중복 페어 제거
↓
레벨2만 추출
↓
레벨2 중복 제거
↓
각 레벨2에 속한 레벨3 목록 구성결과적으로 resultTree는 “어떤 레벨2 밑에 어떤 레벨3가 있는지”를 담는 구조가 된다.
이 구조가 있으면 플로우는 폴더명을 하드코딩할 필요가 없다.
그냥 트리를 돌면 된다.
15.8 WBS 프로젝트 루트 폴더 생성
트리 구성이 끝나면 먼저 업무 프로젝트의 루트 폴더를 만든다.
개념적으로는 다음 위치에 생성된다.
[상위 프로젝트 SharePoint 폴더]/3. [기본폴더] [프로젝트 코드]여기서 3. [기본폴더]라는 접두어는 실제 업무 규칙에 해당한다.
블로그에 공개할 때는 회사 내부 네이밍 정책이면 [기본 폴더 prefix]처럼 가리는 것이 좋다.
루트 폴더를 먼저 만드는 이유는 이후 레벨2/레벨3/산출물 폴더가 모두 이 폴더 아래에 생성되기 때문이다.
15.9 레벨2/레벨3/BP/LL 폴더 생성
그 다음에는 resultTree를 반복한다.
흐름은 다음과 같다.
for each level2 in resultTree
level2 폴더 생성
for each level3 in level2.children
level3 폴더 생성
level3/BP 폴더 생성
level3/LL 폴더 생성이 방식의 장점은 폴더 개수에 상관없이 플로우 구조가 동일하다는 것이다.
레벨2가 3개든 10개든 플로우 구조는 바뀌지 않는다.
레벨3가 10개든 50개든 플로우 구조는 바뀌지 않는다.
마스터 데이터가 바뀌면 반복 대상이 바뀔 뿐이다.

15.10 산출물 폴더 생성
레벨2/레벨3 기본 폴더 구조가 만들어진 후, 산출물 마스터를 다시 반복하면서 산출물 폴더를 만든다.
산출물 폴더 경로는 다음 정보를 조합해서 만든다.
WBS 프로젝트 루트 폴더
+ 레벨2 표시명
+ 레벨3 표시명
+ 산출물명여기서 레벨2/레벨3/산출물명에 /가 있으면 ·로 치환한다.
이 방식 덕분에 레거시의 긴 if 중첩식이 필요 없어졌다.
레거시에서는 산출물의 레벨3 유형을 보고 “어느 폴더 생성 액션의 결과를 참조할지”를 결정해야 했다.
신규에서는 산출물 마스터에 이미 레벨2/레벨3 정보가 있으므로 그 값을 그대로 경로에 사용한다.
비교하면 다음과 같다.
레거시:
산출물 level3Type을 확인한다.
해당 level3Type과 일치하는 폴더 생성 액션의 결과를 찾는다.
그 결과 경로에 산출물명을 붙인다.
신규:
산출물 마스터의 level2Name, level3Name, outputName을 경로에 붙인다.이 차이가 매우 크다.
레거시에서는 산출물 경로 계산이 플로우 구조에 의존했다.
신규에서는 산출물 경로 계산이 데이터에 의존한다.
15.11 폴더 메타데이터 및 ID 조회
산출물 폴더를 만든 뒤에는 해당 폴더의 메타데이터를 조회한다.
그리고 문서 라이브러리 목록을 조회해서 현재 라이브러리의 Drive ID를 찾는다.
이후 생성된 폴더의 UniqueId도 조회한다.
이 값을 Dataverse 산출물 레코드에 저장한다.
이 단계가 중요한 이유는 업무 시스템에서 나중에 해당 폴더를 다시 찾아야 하기 때문이다.
SharePoint 폴더를 만들고 끝내면 사람은 SharePoint 화면에서 폴더를 볼 수 있다.
하지만 시스템은 그 폴더를 안정적으로 식별해야 한다.
그래서 경로뿐 아니라 ID 계열 메타데이터를 함께 저장하는 것이 좋다.
15.12 Dataverse 산출물 레코드 생성
마지막으로 산출물 레코드를 생성한다.
이 레코드에는 대략 다음 정보가 들어간다.
| 정보 | 설명 |
|---|---|
| 산출물명 | 마스터 기준 산출물명 |
| 산출물 코드 | 업무 식별용 코드 |
| 프로젝트 참조 | 현재 업무 프로젝트와의 연결 |
| 프로젝트 유형 참조 | 현재 프로젝트 유형 |
| 레벨2 참조 | 산출물이 속한 레벨2 |
| 레벨3 참조 | 산출물이 속한 레벨3 |
| 폴더 경로 | SharePoint 상대 경로 |
| 폴더 ID | SharePoint 폴더 식별값 |
| Drive ID | 문서 라이브러리 식별값 |
| 필수 여부 | 필수 산출물 여부 |
| 영문명 | 필요한 경우 영문 산출물명 |
이렇게 만들어진 산출물 레코드는 이후 업무 시스템 화면에서 산출물 목록을 보여주거나, SharePoint 폴더로 이동하거나, 파일 업로드 위치를 결정하는 데 사용할 수 있다.
16. 레거시와 신규 구조를 직접 비교하기
16.1 폴더 생성 방식 비교
| 항목 | 레거시 | 신규 |
|---|---|---|
| 레벨2 폴더 | 각 폴더별 액션으로 직접 생성 | resultTree의 level2 반복으로 생성 |
| 레벨3 폴더 | 각 폴더별 액션으로 직접 생성 | level2.children 반복으로 생성 |
| BP/LL 폴더 | 각 레벨3마다 별도 액션 | level3 반복 안에서 공통 생성 |
| 산출물 폴더 | level3Type 조건문으로 부모 경로 결정 | 마스터 데이터의 level2/level3/name 조합 |
| 신규 폴더 추가 | 플로우 수정 필요 | 마스터 데이터 수정 중심 |
16.2 데이터 처리 방식 비교
| 항목 | 레거시 | 신규 |
|---|---|---|
| 마스터 데이터 활용 | 일부 값 조회 후 조건문과 템플릿에 사용 | 폴더 트리와 payload의 기준으로 사용 |
| 중복 제거 | 구조적으로 없음 | union()으로 레벨 페어 중복 제거 |
| 그룹핑 | 없음 | level2 기준 children 구성 |
| payload 구성 | 문자열 템플릿 + 치환 | Compose 객체 |
| 필드 추적성 | 여러 SetVariable을 따라가야 함 | Compose에서 한 번에 확인 가능 |
16.3 유지보수 방식 비교
| 변경 상황 | 레거시에서 해야 할 일 | 신규에서 해야 할 일 |
|---|---|---|
| 레벨3 폴더 추가 | 폴더 생성 액션 추가, BP/LL 액션 추가, 조건문 수정 | 마스터 데이터에 레벨3 및 산출물 매핑 추가 |
| 산출물명 변경 | 마스터와 플로우 경로 계산 영향 확인 | 마스터 데이터 수정, 폴더명 정규화 확인 |
| 프로젝트 유형 추가 | 새 분기 또는 액션 추가 가능성 높음 | 마스터 데이터에 유형별 산출물 등록 |
| 폴더 하위 규칙 변경 | 여러 액션 수정 | 공통 반복 로직 일부 수정 |
| ID 저장 필드 추가 | 템플릿과 레코드 생성 액션 수정 | payload Compose와 레코드 생성 매핑 수정 |
17. 이번 리팩토링에서 배운 점
17.1 “반복되는 액션”은 대부분 데이터 구조로 바꿀 수 있다
레거시 플로우에서 가장 먼저 눈에 띄는 것은 반복되는 폴더 생성 액션이었다.
같은 패턴의 액션이 많다는 것은 보통 둘 중 하나다.
- 반복문으로 바꿀 수 있다.
- 데이터 구조로 바꿀 수 있다.
이번 경우는 둘 다였다.
폴더 하나하나를 액션으로 들고 있을 필요가 없었다.
폴더 목록을 데이터로 만들고, 그 데이터를 반복하면 됐다.
17.2 플로우에 업무 규칙을 너무 많이 넣으면 나중에 고치기 어렵다
Power Automate는 빠르게 자동화를 만들기 좋다.
하지만 그래서 더 쉽게 하드코딩이 쌓인다.
처음에는 “이 폴더 하나만 만들면 되니까 액션 하나 추가하자”로 시작한다.
그런데 그게 반복되면 플로우가 업무 규칙을 모두 품고 있는 거대한 덩어리가 된다.
업무 규칙은 가능하면 데이터로 분리하는 편이 좋다.
이번 작업에서는 폴더 구조의 기준을 플로우가 아니라 산출물 마스터로 옮겼다.
17.3 문자열 템플릿보다 객체 payload가 읽기 쉽다
문자열 템플릿은 빠르게 만들기에는 편하다.
하지만 값이 많아지면 읽기 어렵다.
특히 Dataverse 레코드 생성처럼 필드가 많은 경우에는 payload를 객체로 구성하는 편이 낫다.
객체로 만들면 다음이 편해진다.
- 어떤 필드에 어떤 값이 들어가는지 보기 쉽다.
- 값 하나를 수정할 때 영향 범위를 확인하기 쉽다.
- 레코드 생성 액션과 payload 액션의 매핑 관계가 명확하다.
- 디버깅할 때 Compose 출력만 보면 된다.
17.4 경로 생성 로직은 반드시 정규화가 필요하다
데이터 기반으로 폴더명을 만들면 데이터 품질이 곧 경로 품질이 된다.
그래서 최소한 다음 처리가 필요하다.
- 앞뒤 공백 제거
- 경로 구분자 처리
- SharePoint 제한 문자 처리
- 너무 긴 폴더명 처리
- 중복 이름 처리
- null 값 처리
신규 플로우에서는 /를 ·로 치환하고 trim()으로 공백을 정리하는 구조가 들어갔다.
다만 운영 안정성을 더 높이려면 제한 문자 전체에 대한 규칙을 별도 함수처럼 관리하는 것이 좋다.
17.5 “이미 산출물이 있으면 생성하지 않는다”만으로는 완전한 멱등성이 아니다
신규 플로우에는 중복 생성을 막기 위한 조건이 있다.
현재 업무 프로젝트에 산출물 레코드가 없을 때만 생성이 조건은 필요하다.
하지만 이것만으로 완전한 멱등성이 보장되지는 않는다.
멱등성이란 같은 작업을 여러 번 실행해도 결과가 망가지지 않는 성질이다.
예를 들어 첫 실행에서 다음 상태가 되었다고 하자.
SharePoint 폴더 일부 생성 성공
Dataverse 산출물 레코드 생성 전 실패이 상태에서 다시 실행하면 산출물 레코드는 없으므로 플로우가 다시 실행된다.
그런데 이미 만들어진 SharePoint 폴더 때문에 폴더 생성에서 충돌이 날 수 있다.
따라서 실제 운영에서는 다음까지 고려해야 한다.
- 폴더가 이미 있으면 기존 폴더를 사용한다.
- 레코드가 이미 있으면 업데이트한다.
- 중간 실패 상태를 기록한다.
- 재처리 플로우를 따로 만든다.
- 실패한 프로젝트만 다시 돌릴 수 있게 한다.
18. 마무리
이번 작업은 단순히 Power Automate 액션 몇 개를 줄인 일이 아니다.
기존에는 플로우 자체가 업무 규칙을 직접 들고 있었다.
어떤 폴더를 만들지, 어떤 레벨3 아래에 산출물을 넣을지, 어떤 산출물을 만들지 같은 규칙이 플로우 안에 하드코딩되어 있었다.
신규 구조에서는 그 기준을 산출물 마스터 데이터로 옮겼다.
그래서 플로우는 더 이상 모든 폴더명을 직접 알 필요가 없다.
플로우는 데이터를 읽고, 중복을 제거하고, 트리를 만들고, 반복해서 폴더와 레코드를 생성하면 된다.
이런 리팩토링은 처음에는 시간이 더 걸린다.
그냥 폴더 생성 액션 하나 더 붙이는 것이 훨씬 빠르게 느껴진다.
하지만 자동화가 오래 운영될수록 차이가 커진다.
- 새 폴더가 추가될 때
- 프로젝트 유형이 늘어날 때
- 산출물 마스터가 바뀔 때
- 폴더명 규칙이 바뀔 때
- 운영 환경을 분리해야 할 때
- 실패를 복구해야 할 때
하드코딩된 플로우는 점점 더 무거워진다.
데이터 기반 플로우는 상대적으로 변경 지점이 명확하다.
이번 리팩토링의 가장 큰 의미는 여기에 있다.
자동화가 “일단 돌아가는 상태”에서 “바꿀 수 있는 상태”로 바뀌었다.
'인턴' 카테고리의 다른 글
| [Azure] CRM 리치 텍스트 이미지 저장 구조 개선기: Dataverse에서 Azure Blob Storage로 (0) | 2026.06.07 |
|---|---|
| [Azure] Azure 학습 및 고객사 아키텍처 설계 문서 (10) | 2026.06.07 |
| [MCP] Remote MCP 기반 OpenAI–Dataverse 데이터 접근 아키텍처 (0) | 2026.06.05 |
| [MCP] Microsoft - Dataverse MCP 설치 방법 정리 (클로드 코드 기준) (0) | 2026.06.05 |



