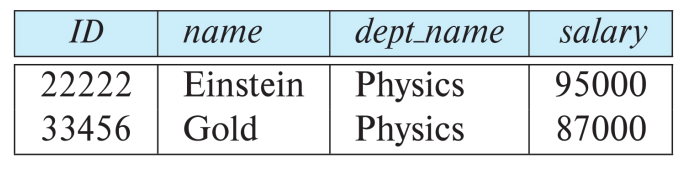
Example of a Instructor Relation
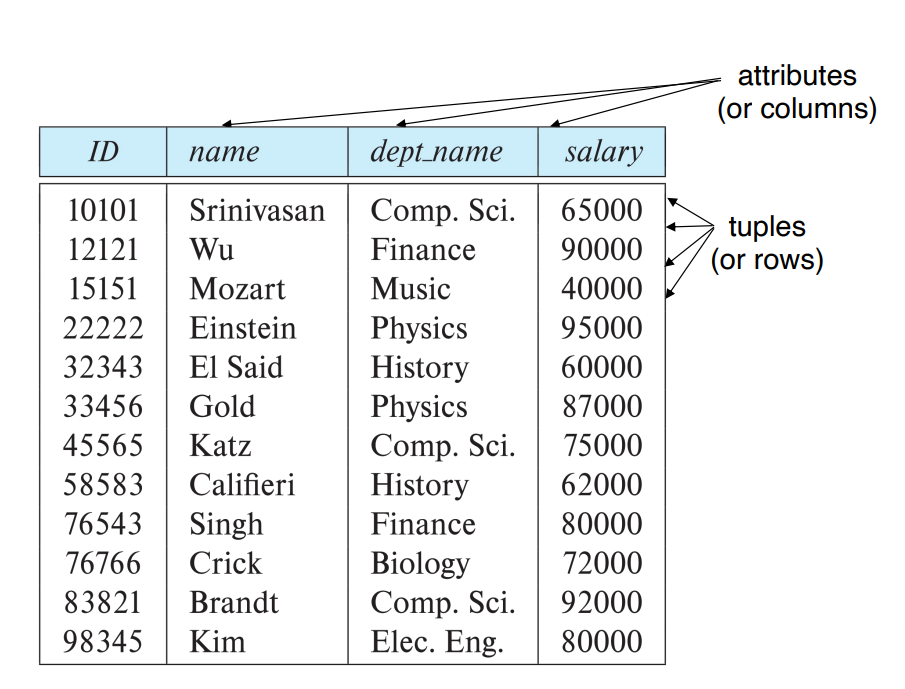
속성(Attributes): ID , name , dept_name , salary
튜플(Tuples): 각 행/ (10101, Srinivasan, Comp. Sci., 65000) , …
관계(Relation)은 테이블 형태로 표현한다.
각 열은 속성, 각 행은 튜플
위 테이블은 instructor(ID, name, dept_name, salary) 라는 관계 스키마(Relation Schema)를 따른다.
Relation Schema and Instance
관계 스키마 (Relation Schema)
관계 스키마(R)는 테이블의 형태를 정의한다.
A₁, A₂, ..., Aₙ은 속성들이라고 하자.
R = (A₁, A₂, ..., Aₙ)은 관계 스키마(R)를 의미한다.
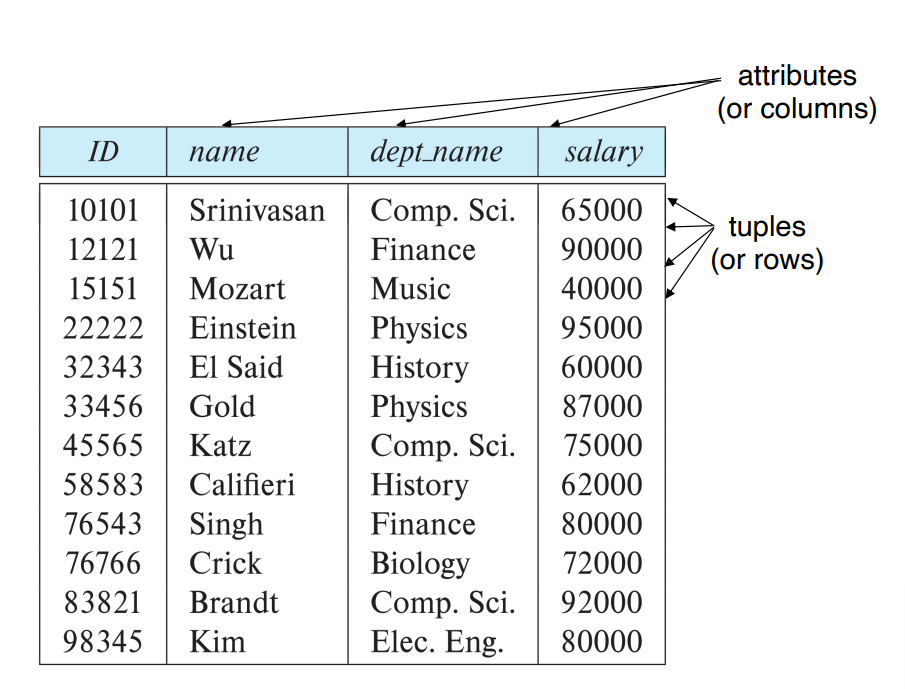
위 사진의 관계 스키마(instructor) 는 아래와 같다
instructor = (ID, name, dept_name, salary)
관계 인스턴스 (Relation Instance)
r(R) 로 표현한다.
스키마 R 위에 정의된 실제 데이터의 집합을 말한다. 걍 딱 지금의 테이블 의미한다.
스키마가 테이블의 형태라면 인스턴스는 내용을 말함.
관계 인스턴스 r 의 한 원소 t는 하나의 튜플이다. (튜플은 한 행)
Attributes
도메인(Domain)
어떤 속성이 가질 수 있는 값들의 집합
salary → 양의 정수
dept_name → 문자열의 enum
원자성(Atomicity)
속성 값은 더 이상 나눌 수 없어야 한다.
- 하나의 속성은 반드시 하나의 값
- 하나의 속성 값을 서브값으로 분해할 수 없어야 함.
null 값
모든 도메인에 포함될 수 있는 특수한 값
의미는 알 수 없음(unknown)의 의미
null을 자주 쓰면 계산이 비싸지는데, 어쩔 수 없을 땐 진짜 어쩔 수 없이 쓴다.
Database Schema
Database Schema
데이터베이스의 논리적 구조(어떤 테이블 들이 있고, 어떤 속성들이 있는지 정의)
관계 스키마는 하나의 테이블을 정의 했다면 데이터베이스 스키마는 여러 개의 관계 스키마와 이들의 연결정보까지 포함한다.
Database instance
주어진 시점에서 실제로 저장된 데이터를 말한다. 다시 말해서, 주어진 시점에서 테이블안에 들어있는 값들
데이터베이스는 얼마든지 변형될 수 있다
Keys
Superkey
어떤 속성 집합 K⊆R 이 있을 때, 집합 K가 튜플들을 유일하게 식별할 수 있게 해주면 K는 슈퍼키이다.
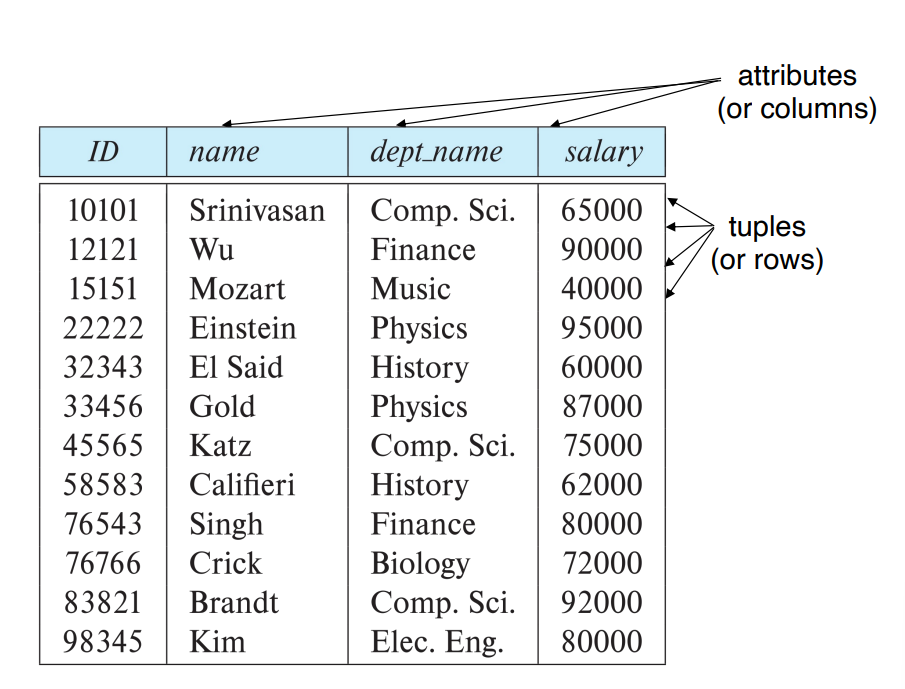
ID 는 유일하니까 슈퍼키 가능!
{ID, name} 는 이름이 추가되어도 여전히 유일하니까 가능! (하지만 효율 떨어짐)
Candidate Key
슈퍼키 중에서 더 이상 속성을 제거할 수 없는 최소한의 집합
딱 액기스만 가진 슈퍼키를 후보키라고 함.
Primary Key
여러 후보키 중에서 대표로 선택된 키
걍 후보키 중에서 알아서 고르면 됨
Foreign Key
한 관계에서 속성이 다른 속성의 주요키를 참조하는 경우
관계형 데이터베이스에서 관계 간의 연결을 위해 사용함
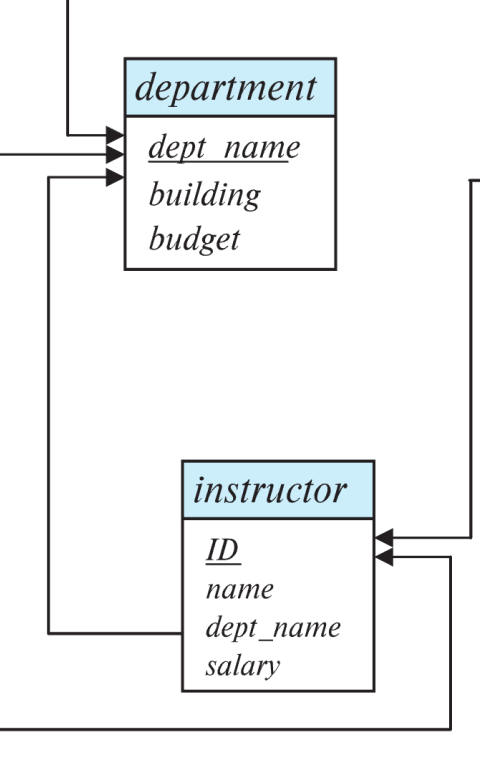
여기서 instructor 의 외래키는 dept_name .
instructor 테이블은 department 테이블을 참조하고(Referencing)있다.
department 테이블은 instructor 테이블에게 참조되고(Referenced) 있다.
Relational Algebra
select: σ
튜플 중에서 조건을 만족하는 것만 선택
입력: 하나의 관계 (테이블)
출력: 조건을 만족하는 튜플만 포함한 새 관계 (테이블)
쿼리: σdept_name="Physics"(instructor)
⇒ instructor 테이블에서 dept_name=”Physics” 를 select 해라!
⇒ table로 리턴함
스키마는 instructor랑 같은 걸로
|
연산자
|
의미
|
|
=
|
같다
|
|
≠
|
같지 않다
|
|
>, <
|
크다, 작다
|
|
≥, ≤
|
크거나 같다, 작거나 같다
|
|
연산자
|
의미
|
|
∧
|
AND (그리고)
|
|
∨
|
OR (또는)
|
|
¬
|
NOT (부정)
|
연산자는 충분히 많이 다 조합 가능
σdept_name="Physics"∧salary>90,000(instructor) 요런 식으로
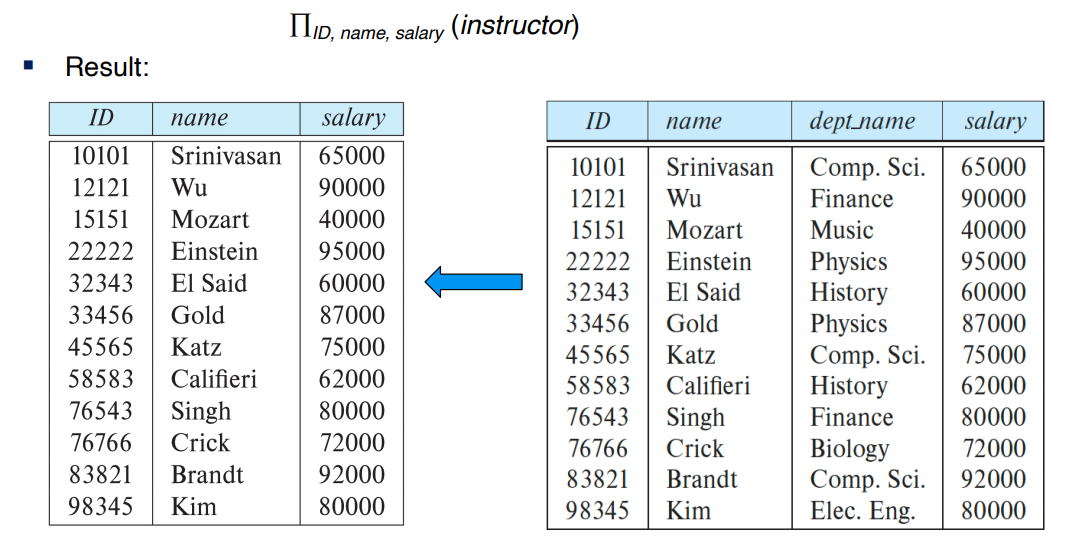
project: Π
속성만 뽑아내는 연산
조건 없이, 원하는 속성들만 선택하고 나머지는 제거
새로운 테이블을 반환함
Cartesian Product: X
카테시안 프로덕트는 두 릴레이션 R과 S의 모든 가능한 튜플 쌍을 나열하는 연산이다.
두 테이블에 attr이라는 속성 이름이 겹치면 새롭게 만들어진 테이블에는 R.attr와 S.attr이 속성으로 들어간다.
Join Operator
조인은 두 릴레이션의 카테시안 프로덕트에 선택 연산을 적용한 것으로 정의할 수 있다.
σinstructor.id=teaches.id(instructor × teaches.id)
이런 식으로 작성하면 두 릴레이션을 카테시안 프로덕트로 ㅈㄴ게 많은 튜플을 만들고 여기서 intructor.id = teaches.id인 녀석들만 골라내면 된다.
관계형 디비에서 조인이 시간이 가장 오래 걸린다.
표현 방식
- σθ(r×s)
- r⋈θs
이걸 세타 조인이라고 한다.
σinstructor.id=teaches.id(instructor × teaches.id) 는 다음과 같다.
instructor⋈instructor.id=teaches.idteaches
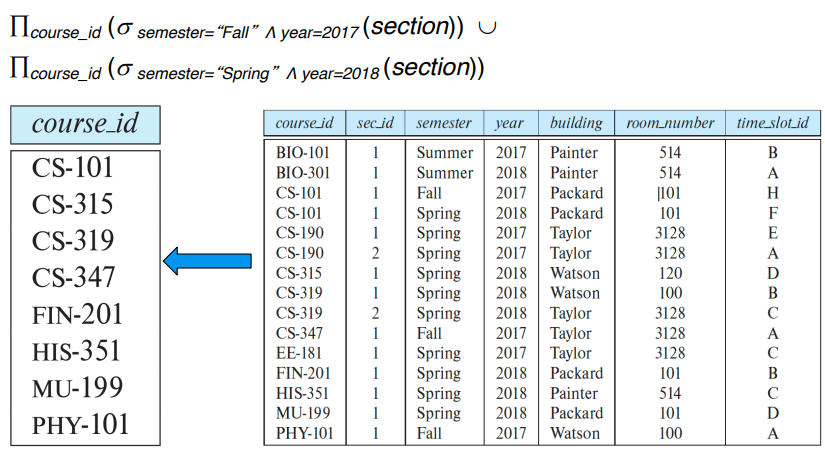
Union Operator : ∪
두 릴레이션의 합집합
조건 2가지 존재
- 두 릴레이션 r과 s는 속성의 개수가 같아야 함
- 속성이 compatiable 해야 함 (타입이 같아야 한다는 말)
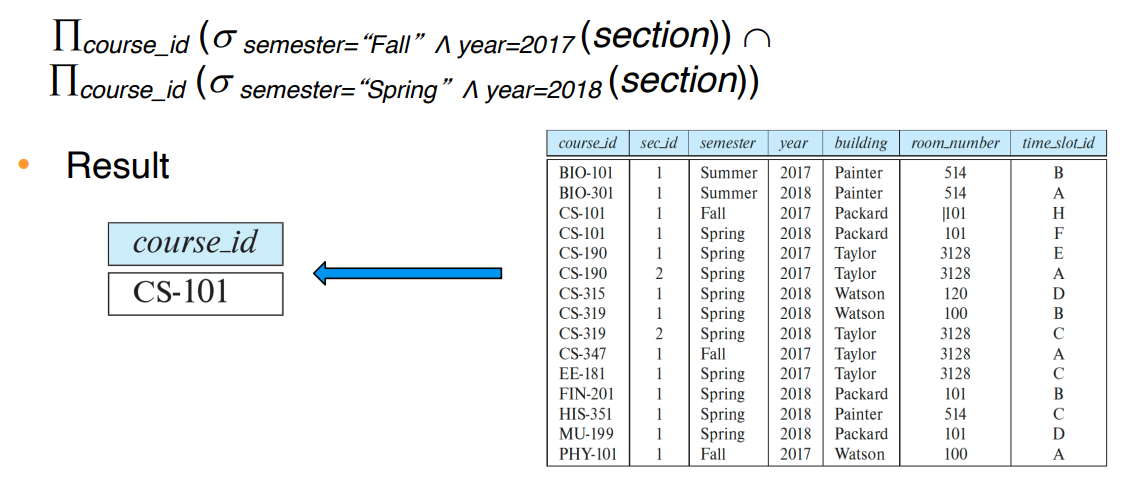
Set-Intersection Operator: ∩
유니온의 반대.
교집합만 추려냄
조건 2가지 존재
- 두 릴레이션 r과 s의 속성의 개수가 같아야 함
- 속성이 compatiable 해야 함 (타입이 같아야 한다는 말)
Set-Difference Operator: −
걍 두 집합 빼기
차집합.
Assignment Operator: ←
걍 변수 할당하는 것처럼 연산의 결과를 어떤 문자에 할당하는 것
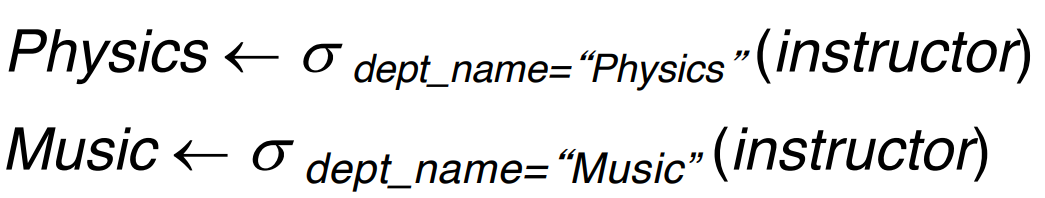
Rename Operator: ρ
관계 대수에 임시 이름을 붙이기 위해서 사용하는 연산이다
ρx(E) 라고 작성하고 결과의 이름을 x 라고 부른다.
속성의 이름까지 바꾸고 싶다면 ρx(A1, A2, .. An)(E) 로 표현한다.
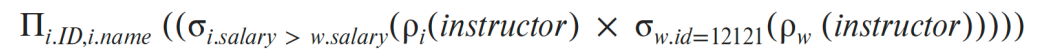
'지식 > 데이터베이스시스템' 카테고리의 다른 글
| Database Design Using the E-R Model (1) | 2025.03.30 |
|---|
