Creating a network app
edge 라인에 있는 엔드 유저가 쓰는 라인이 application layer
core network의 인프라를 그대로 이용하면서 엔드 시스템에서 돌아가는 코드만 짜면 됨
이렇게 하면 빠르게 프로그램이 개발됨. = high level programming
application layer는 core 파트는 생각하지 말고 너 자신에서의 개발에 충실해라
core 파트는 걱정하지 말고 함수로 다 불러라
라이브러리만 알고 있으면 된다
(옛날에는 이게 안되서 오래걸리고 복잡했음)
레이어링을 통해서 엔드 단에서만 프로그래밍을 하면 되는 상황이 되었다.)
논리적으로 연결 당연하다고 가정하고 코딩
application layer가 다른 application layer와 다이렉트로 연결되어있다고 생각하고 코딩해라
Application architecture
네트워크 아키텍쳐는 2가지
- 클라이언트 - 서버
- p2p
Processes Communicating
IPC 프로그래밍: OS에서 배움
이거 한번 에러나면 디버깅이 어려움. 세마포 개념 들어가서 정신 차려서 프로그래밍 해야됨
IPC 프로그래밍은 하나의 서버가 있는데 이 서버 안에 멀티 프로세스인 상태
프로그램은 디스크 안에 들어가 있는 상태
프로세스는 로더에 의해 메모리에 올라와서 cpu가 실제로 동작하는 상태
서버가 성능이 좋아서 수 많은 프로세스를 띄움
이 수 많은 프로세스들이 서로 통신하는게 IPC.
클라이언트와 서버의 각각의 프로세스들이 통신을 함.
서버는 데이터 센터와 같은 개념. 항상 전원이 있는 상태 서버는 꺼져있는게 말이 안된다.
서버는 항상 클라이언트 쪽의 프로세스가 시작하길 기다리고 잇음
클라이언트는 통신해야지 하고 신호를 주는 것
P2P는 각자의 peer가 서버가 되었다가 클라이언트가 되었다가 왔다 갔다 하는 것.
서로 다른 머신에서 프로세스끼리 통신할 때는 메시지를 걸 통해서 왓다갔다 함.
Application layer는 자기 아래 layer는 무시하고 socket을 통해서 내보냄.
socket은 door 역할을 한다.
메시지를 생성했는데 문을 통해서 내보낸다
socket을 함수로 불러서 메시지를 보내는 것
메시지를 보내려고 하는 센더 쪽의 머신은 인프라 스트럭쳐에 의존해서 보내는데 상대는 인프라에 대해서는 깊이 알 필요가 없음. 나는 socket 함수만 부르면 됨.
Addressing proccesses
철수가 영희한테 메시지를 보낸다
application은 로직컬하게 다이렉트로 연결되었다고 생각함
근데 사실은 그렇지 않음
네트워크를 통해서 하는 것임
이럴 때 메시지가 상대쪽을 찾아가야함
어떻게 찾아감????????????????
철수의 프로세스가 영희의 프로세스를 어떻게 identifing 하는지?
아이텐티파이어를 가지고 함
식별하기 위해서는 IP address 라는 고유한 번호를 통해서 식별함.
아이피 주소는 고유한 번호
이 주소는 호스트(에이전트)를 식별할 수 있는 유일한 식별자 역할을 함.
근데 주소로 머신을 찾아갔다고 하더라고 어떤 프로세스인지 딱 집어줘야 하는데 이거는 어떻게 하나?????????
이건 포트 번호를 통해서 식별함.
프로세스까지 찾아가려면 IP주소랑 포트 번호까지 알아야 가능함.
포트 번호 겹치면 쫑남
이미 찜된 애들 빼고 포트 번호를 사용해야함 포트 번호는 외울 필요 없음
Application layer protocol defines
어플리케이션을 돌리려면 프로토콜을 만들어야함 ⇒ RFC 작성해서 제출하면 됨
만들려면 정확하게 내용을 기술해야 함
- 메시지가 교환할 때 어떤 타입인지
- 문법이 어떤지
- 메시지 시멘틱
- 룰
프로토콜 방법
- 오픈 프로토콜: 누구나 쓸 수 있는 프로토콜
- 소유권 있는 프로토콜: 특정 회사 전용의 프로토콜
What transport service does an app need?
우리가 메시지를 집어 넣어서 보낼 때 데이터 무결성이 필요하다!!!!!!!!!!!!!!!!!!!!!
데이터가 엄청 크더라도 문제가 없어야 함. real time (오디오, 비디오 는 큰 문제가 없음)
두 번째로는 출발한 데이터는 일정 시간 안에 도착을 해야 함.
일정 딜레이를 넘어가면 의미가 사라짐
mayday 이런건 바로바로 가야 한다.
세 번째로는 트루풋
많이 보내면 좋은 것 = 다다익선
그래도 미니멈은 보내야 한다.
예를 들어서 초당 ~~KB는 가야 한다.
문서 위주의 앱들은 데이터 무결성을 보장해야함
유언장이 삑나면 되겠음??
real time은 패킷 로스 어느정도는 ㄱㅊ
데이터 무결성이 필요하다면 나중에 transport layer의 TCP, 그게 아니면 UDP
Interner transport protocols services
transport layer에서 메시지를 보내지 위해 구현하는데, 2가지 방법 있음 (프로토콜)
- TCP
- UDP
TCP
데이터 무결성이 필요한 프로토콜
reliable transport = 보내고 맞는 쪽이 보장되어야 함
받았다는걸 컨펌이 필요함
flow control = 트래픽 컨트롤을 정교하게 한다
congestion cotrol = 트래픽 컨트롤을 정교하게 한다.
타이밍과 미니멈 트루풋을 제공하지 않음
개런티도 없다 이건 UDP도 없음. 네트워크에서 뭔 게런티 ㅋ
connection-oriented
센더와 리시브와 사전 합의. 보내고 받는 사전 합의
UDP
타이밍이 중요하다
unreliabel transport: 받으면 좋고 패킷 로스되고 노상관
TCP가 제공하는 거 다 제공 안함
최선을 다했지만 책임은 못집니다 ^^
Web and HTTP
프로토콜 별로 설명한다
HTTP
어플리케이션 레이어에서 작동하는 프로토콜
이건 웹 페이지가 어떻게 표현이 될 건지 정의해 놓은 프로토콜
웹 페이지가 여러 객체로 구성되어있는데 이걸 화면에 어떻게 디스플레이 할지 결정해 놓은 것
우리가 웹 접속할 때 URL을 우리는 클릭함.
우리가 풀 URL 풀 네임 직접 쳐서 접속하지 않음.
바로 이게 HTTP 프로토콜
우리 에이전트에서 웹 페이지로 홈페이지를 보여달라는 요청을 보냄
요청이 수락되면 클라이언트로 소스코드가 쭉 오게됨
이걸 쭉 읽고 프로토콜에 맞게 디스플레이를 해줌.
그럼 내가 보는 것
HTTP 자체는 어플리케이션 자체의 프로토콜
transport는 어떤 프로토콜을 사용하냐면 TCP를 사용함
유저는 TCP를 사용해서 서로 연결을 만들고 실제 객체를 읽고 디스플레이함.
HTTP는 stateless다.
모든 상태를 기억하지 않는다.
과거에 클라이언트가 어떤 요청을 했는 지에 대한 정보를 기억하지 못한다.
non-persistent HTTP
한 페이지에 수 많은 오브젝트들이 들어 있음
옛날에는 99퍼는 문서였음
점점 화려해지니까 그림도 들어가고 영상도 들어가고 광고도 들어감
이게 다 오브젝트
처음에는 오브젝트 하나하나 보낼때마다 TCP 매커니즘을 적용함
하나 보낼때마다 완벽함을 요구
커넥션을 만들고 자료를 보내고 잘 받았는지를 확인 (하나 하나 이걸 다 함)
수 많은 오브젝트들이 병렬적으로 쭉 가야하는데, 그렇지 못함
내가 어떤 사진을 띄울려고 할때 non-persistent 하면 내가 연결 해도됨? 물어보고 커넥션이 허락되면 내가 오브젝트를 띄우고 싶어요!! 요청을 함 그러고 나서 허락 받으면 오브젝트를 받음.
- initial TCP connection
- 허락 신호 보내기
- 나 어떤 오브젝트 주셈
- 줄게 ^^라는 신호 보내기
- 파일 전송
⇒ 2번의 RTT + file transmission
이렇게 하면 홈페이지는 사진 하나당 한번씩은 물론이고, 문서 띄울 때마다 한번, …. 오래걸림
그래서 persistent하게
persistent HTTP
커넥션을 연결하면, 병렬적으로 보내지는 것.
한 오브젝트 갈때마다 2번의 RTT는 개에바임
이거 1번으로 줄이자
만약 한 페이지에 오브젝트가 3개 있다고 하면 이니셜은 RTT 한번 하고 그 다음부터는 이니셜 빼고 RTT 갈기자
그러면 2번째부터는 RTT 1번만 하면 됨.
커넥션이 끝났다고 할 때까지는 끄지말고 계속 오픈해놓고 오브젝트 요청이 올 때마다 바로바로 보내주기
이러면 오버헤드가 줄어들겠다!!!!!!!!
User-server state: cookies
웹 서비스의 쿠키!!!!!!!!!!!!!!1
나에게 맞는 상품 추천!!!!
쿠키의 정보
어떤 클라이언트가 어떤 서버에 접속하면 클라이언트의 아이피에 대한 정보를 저장해 두고 여기에 해당하는 아이피로 접속이 이루어지면 이에 대한 정보를 로컬에 저장함.
다음에 접속하면 이 텍스트 파일이 서버에 가서 사용자에 대한 디비를 만들고 이걸 기록해 둠.
이게 state 다. 다 저장해 놓는다
Web caches (proxy server)
프록시 서버의 공식 명칭이 웹 캐시
캐시를 통해서 별로 돈을 들이지 않고 시스템 성능을 굉장히 높일 수 있다.
여러 클라이언트가 데이터를 요구하는데 실제 서버는 멀리 떨어져 있다.
가만 보니까 핫이슈인 데이터는 얼마 안됨. (인기 있는 컨텐츠들)
그러면 찐 서버까지 왔다 가는 것보다 한국인들이 많이 찾는 데이터를 저장해 둔 데이터 센터를 한국에 두고 미국까지 갈 필요 없이 한국 안에서 엑세스 하면 되겠다!
로컬리하게 해결!!!!!!
물리적으로 가깝게 하는 것!!!!!!!!
오리진 서버 내용을 프록시 서버에 캐시하자
근데 프록시 서버에 없으면???
그제서야 프록시 서버가 오리지날 서버에 그 데이터를 요청함.
그러면 프록시 서버는 그 데이터를 받아서 캐시함
캐시는 ISP들이 설치
프록시 서버는 클라이언트와 서버의 역할을 동시에 한다.
Caching example
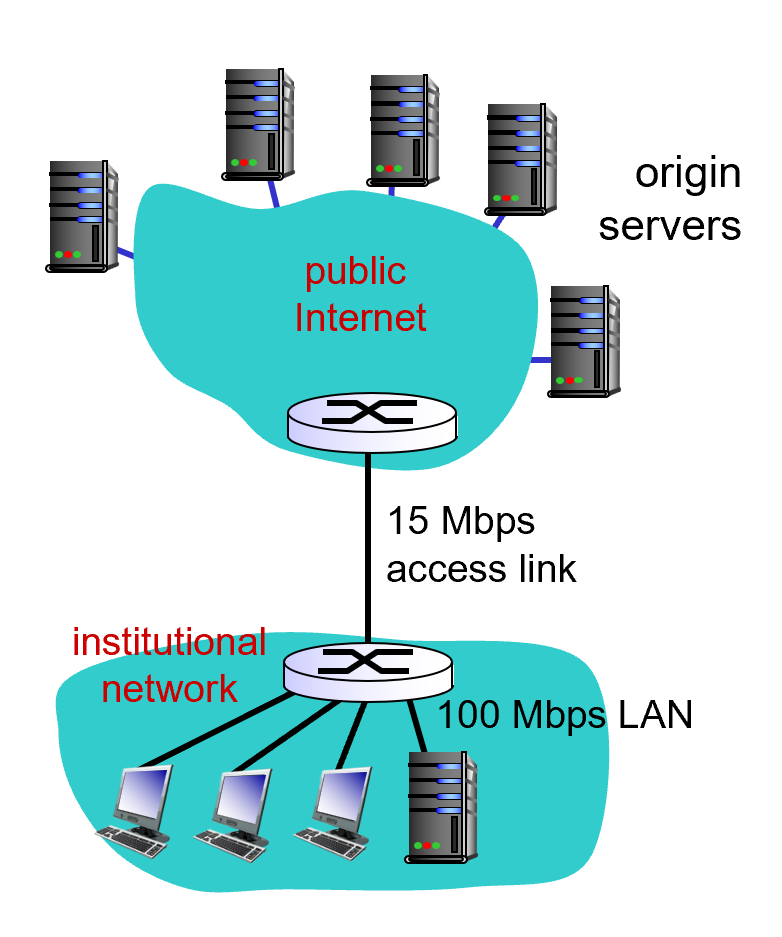
public network : 지구 전체를 감싸고 있는 네트워크
institutional network : 에 있는 라우터는 엑세스 네트워크의 라우터
가정
- 평균 오브젝트 사이즈 : 1Mbits
- 브라우저가 오리진 서버에 보내는 요청 : 15Mbits/sec
- RTT (엑세스 네트워크 라우터 부터 오리진 서버): 2sec
- access link rate: 15Mbps
밴드위드는 15Mbps 필요한데 로컬 에리아 네트워크에서는 100Mbps 니까 15% 정도 밴드위드만 사용하는거니까 문제 없음
근데 어떤 오리지날 오브젝트는 오리진 서버에 있어서 오리진 서버를 갔다와야함
근데 이 시간이 RTT로 2초 걸린다고 함
근데 한국과 미국을 연결하는데 어떤 바틀넥 구간이 15Mbps 이면 큰일이 나는거임
내가 요구하는 양이 15Mbps인데, 링크의 맥시멈 커패시티가 15Mbps면 저 바틀넥 구간은 100%을 쓰는 것임
이러면 딜레이가 분 단위로 걸리게 됨.
이 시나리오에서는 평균 1Mbits가 초당 15개씩 요구되었을 때 토탈 걸리는 시간은
⇒ 2초 + 마이크로초 + 바틀넥 분 단위
분 단위가 문제야 문제
해결책은 돈이 많은면 15Mbps 말고 150Mbps 깔면 걍 해결됨
근데 진짜 비싸
그래서 웹 캐시!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
로컬 웹 캐시 하나 설치하는데 천만원도 안든다 개꿀
이 웹 캐시가 들어왔을 때 100%가 다 프록시에서 엑세스 되는건 아닐거다.
보통 요청의 40퍼가 웹 캐시로 엑세스 가능
60퍼는 오리진 서버
그러면 15Mbps 중에서 60퍼는 9Mbps인데 이 정도는 견딜만 하다고 판단. (아까는 거의 100%였자나)
시간도 15Mbps가 RTT 하는데 2초였으니까 이 시간도 60퍼만 쓰는것
그러면 토탈 딜레이도 같이 줄어들게 된다.
Conditional GET
웹 캐시도 데이터가 최신화가 되어야 하잖아?
어떻게 업데이트 하지??
옛날에는 일정 시간 되면 오리진 서버에서 걍 데이터를 우루루 가져왓음
근데 이게 너무 비효율적임
그래서 HTTP 같은 곳에는 명령어가 있음
Conditional GET
프록시 서버가 오리진 서버에 물어봄
“나 이 객체 가지고 있는데 이거 업데이트 됨??”
변형이 일어난 시간을 비교해서 변형이 일어났으면 가져오고 아니면 걍 둠
데이터의 수정이 있으면 가져오고 아니면 놔두고
Electronic mail
어플리케이션 레이어에서 가능 중요함 프로토콜
- SMTP
- POP3, IMAP
일렉트릭 메일은 어플레케이션 레이어에서 서포트하는 여러 어플리케이션 중에 가장 유명한 녀석
이메일을 서포트하기 위한 프로토콜의 가장 주요한 3가지 요소
- user agent
- mail server
- SMTP
이메일 서비스는 문서가 왔다 갔다 하는거라서 데이터 무결성이 보장되어야한다
그래서 이메일 서비스는 TCP로 한다.
내가 메일을 쓰면 (메일 보내기) 하면 내 웹 서버로 감. (SMTP)
내 웹 서버에서 상대 웹 서버로 메일을 보냄 (SMTP)
밥은 자기 웹 서버에서 메일을 자기 앞으로 끌어옴(POP3, IMAP)
HTTP는 풀임
클라이언트 쪽에 가서 강제로 요청해서 끌어오는 것임
내가 어떤 웹 서버에 접속했을 때 화면이 나온다는 것은 HTTP 서버에 가서 강제로 오브젝트를 뜯어오는 것
HTTP는 각 오브젝트가 하나하나 캡슐화되어서 분산되어서 들어감
SMTP는 푸쉬임
클라이언트는 가만히 있는데 서버가 밀어서 주는 것
SMTP는 내가 메일에 첨부 파일로 이미지, 동영상, 사진을 넣으면 하나로 뭉뜽그려서 보내짐
보내는 쪽에서 받는 사람의 서버까지 커버하는게 SMTP
받는 사람 서버에서 에이전트까지 커버하는게 POP3, IMAP
DNS
domain name system
내가 sogang.ac.kr 이라고 치면 기계는 이걸 가지고 에이전트가 sogang.ac.kr의 IP address가 어떻게 됨??
이렇게 물어보면 DNS가 알려줌.
DNS 프로토콜로 운영되는 DNS 서버가 알려줌
결국 데이터 통신하기 위해서 머신 대 머신이 매핑 되어야 하는데 이걸 외우기 힘드니까 특정 이름으로 해놓고 그 이름이 가지고 잇는 진짜 아이피 주소를 제공해주는 시스템이다.
우리가 맨 처음에 인터넷에 접속하면 가장 먼저 들어오는게 한 홉 거리에 있는 라우터의 아이피 주소와 나와 가장 가까운 DNS 서버의 주소가 들어옴
예를 들어서 나를 식별하는게 있음, 학번, 주민번호, …
마찬가지로 인터넷도 인터넷 디바이스들도 아이피 주소가 있는데 이걸 외우기가 힘드니까 구글 닷컴, 야후 닷컴 하는 거임
문제는 야후 닷컴의 찐 아이피 주소가 뭔지 기계가 알 수 있도록 해야함
그래서 이걸 알 수 있도록 인터넷 처음 만드는 사람들이 DNS라는 프로토콜을 만들면서 설계를 함
“전 세계가 하나로 통합되는데 아이피 주소 외우는 건 말이 안되니까, 이름을 붙여서 이걸 매핑해서 돌아가게 하자”
지구를 13개 조각으로 나눔
여기에 DNS service를 해주는 서버를 가져다 놨음
distributed database
13군데에 디비를 분산시켜놓음
이게 DNS server의 최상위단임
내가 amazon.com을 치면 이거에 대응하는 호스트 이름은 1개임
근데 이거에 매칭되는 서버는 수십 수백 수천 수만개될거임
아마존 닷컴이라는 이름을 가진 웹 서버는 엄청 많음 전 세계에 깔려있음
똑같은 이름을 가진 서버가 수만개 있으면 내가 접속하면 어디로 접속이 되냐?
⇒ 나랑 가장 가까운 효율적인 루트로 접속이 됨
내가 아마존 닷컴해서 딱 들어가려고 하면
가장 가까운 DNS 서버에 들어감.
그 밑에 TLD 서버를 둠 (com인지, org인지, edu인지, …)
그 밑에 Authoricated 서버를 둠
- TLD
- Authoricated
사실은 어떤 질문이 있을 때, root DNS로 가기 전에 로컬을 책임지는 Local DNS name server로 감
대부분 여기서 다 커버가 됨.
우리가 호스트 네임 치면 root DNS 서버 가는게 아니라, Local DNS 서버로 감.
근데 로컬 DNS 서버는 어케 알고 감????????
ㄱㅊ, 인터넷 연결되는 순간 자동으로 들어옴
로컬 DNS 서버 설치는 ISP 들이 함, 서강대학교도 서강대학교 DNS 서버가 있을 거임
이 로컬 DNS 서버는 프록시 같은 느낌의 역할을 한다.
대부분 로컬 DNS 서버에서 처리가 되는데 진짜 이상한 웹 사이트를 가려고 한다???
그러면 로컬 DNS 서버는 모르기 때문에 그제야서 root DNS 서버로 감.
- 반복적 (이터레티브)
- 재귀적 (리컬시브)
근데 이 DNS 서버가 하도 똑같은 요청을 받으니까 자주 묻는 사이트는 캐시 안에 저장을 해 둠
그러면 캐시의 최신 정보는 어떻게 유지함????
TTL 개념을 넣어서 time to arrive, 20분 정도로 해놓고 새로운 엑세스가 오지 않으면 캐시에서 삭제함
TTL을 설정해서 그 시간동안 엑세스 되지 않은 캐시 내용을 삭제함
이거는 특정 아이디어가 있어서 그런게 아니라 매커니즘을 그렇게 설정을 해놨다.
Pure P2P architecture
- 항상 켜져 있는 중앙 서버가 없다 (no always-on server)
- 임의의 사용자(엔드 시스템)끼리 직접 통신
- 피어(사용자)는 연결이 끊기기도 하고, IP 주소도 자주 바뀜
예를 들어서 토렌트 = 파일 디스트리뷰션
File distribution: client-server vs P2P
클라서버 메카니즘은 서버가 존재하고 얘는 항상 서버임
그 다음에 네트워크가 연결이 되어있다.
우리가 어떤 파일을 분배하려고 할 때, 어떤게(클라서버, 피투피) 더 성능이 좋을까??
client-server
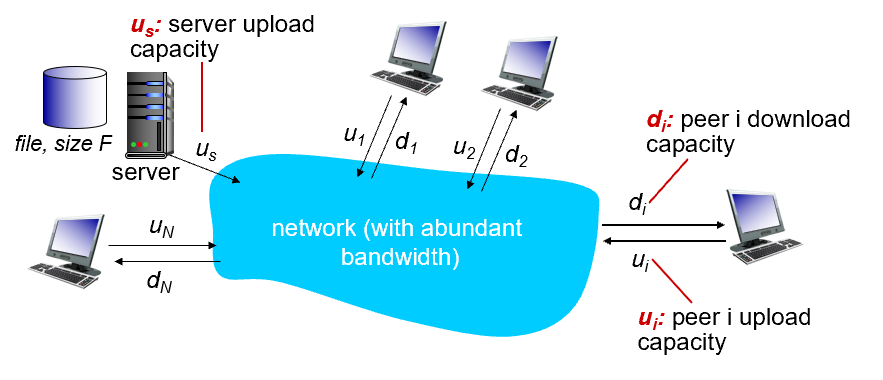
서버가 파일을 가지고 있음
파일의 사이즈는 똑같다고 하자
근데 파일 A,B,C,D, … n개 있다고 하자
서버가 n개의 파일을 가지고 있다
그리고 n개의 클라이언트가 있음
클라이언트들은 이 네트워크에 자기만의 벤드위드로 참여함
업로드 밴드위드는 내가 업로드할때 사용되는 밴드위드
다운로드 밴드위드는 내가 다운로드할때 사용되는 밴드위드
우리(클라이언트)는 보통 다운로드를 많이 함.
근데 서버는 보통 업로드를 많이 함
서버가 n개의 파일을 가지고 잇고 파일을 n개의 클라이언트에 1개씩 분배함
n개의 파일은 u_s에 맞춰서 파일을 올려줌
그때 딜레이는????????????? 트렌스미션 딜레이는??????????
전체 파일 사이즈를 밴드위드로 나눠줘야지 이걸 전체 올리는데 걸리는 시간을 구함.
용량이 F인 N개의 파일을 올리려면 NF/u_s 임.
1번이 올라가면 1번은 다운로드됨 2번이 올라가면 2번이 다운로드됨 그 동안 다른 애들은 쉬는 중
다운로드 하는 밴드위드가 서로 다르다고 햇을 때 어디가 바틀넥이 걸리나??
가장 다운로드하는 밴드위드가 작은 녀석!!

이게 당연한게 아님. 서버가 업로드하는 밴드위드는 보통 엄청 큼
예를 들어서 서버가 10개의 파일을 업로드 하는데 1분걸렸다고 하더라도 엄청 열악한 녀석의 다운로드가 10분 걸린다고 치면 이 녀석 때문에 토탈의 파일 분배가 느려지는 것임
P2P
서버가 트랜스미션을 함.
근데 한 서버가 n개의 파일을 모두 가지고 파일을 분배하는 것이 아니라 서버도 가지고 있을 수 있지만 다른 클라이언트도 가지고 있을 수 있음.
그래서 서버도 피투피 아키텍쳐에 파일을 올리고, 다른 피어들도 자기가 가지고 잇는 파일을 올리게 됨
이떄 서버도 올릴 수 있고, 다른 피어들도 올릴 수 있다.
이때도 다운로드 하는데 가장 바틀넥이 걸리는 녀석이 걸리는 시간이 지배적일 수 있음
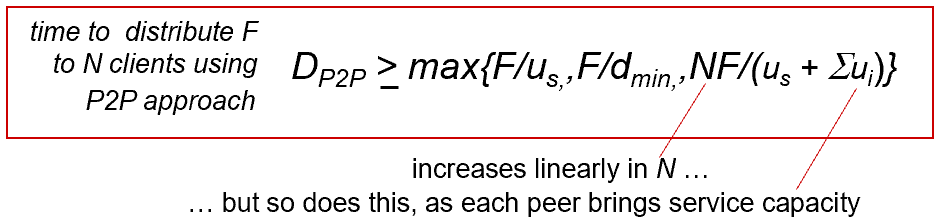
여기서 중요한건 클라서버와 피투피의 n이 증가할때 그래프가 어떻게 그려지는지
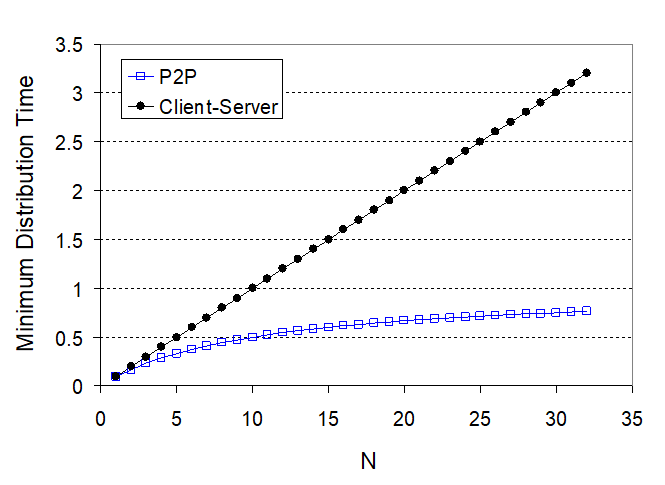
적을때는 노상관인데 파일이 많아지면 피투피가 대박임
P2P file distribution: BitTorrent
여기서 피투피 중에 가장 유명한 제품이 비트토렌트라는 프로토콜을 사용한 어플리케이션
비트 토렌트라고 하면 비트 토렌트를 돌리는 프로토콜이라는 뜻도 되고 어플리케이션이라는 뜻도 됨
피투피에는 트래커라는 시스템이 있음
얘는 피어들의 리스트를 관리하는 녀석임
엘리스가 비트 토렌트에 접속해서 찾고 싶은 파일을 검색한 것임
얘가 존재하는데 가장 가까이 있는 트래커에 접속이 됨
이 트래커는 리스트를 줌
이 리스트에는 엘리스가 원하는 파일을 가지고 있을 만한 가장 가까이 있는 피어들의 리스트
그러면 이때는 엘리스라는 애가 리스트에 있는 애들한테 연락을 함
얘네들을 이웃이라고 함. 네이버
얘네들한테 파일 요청을 함. 파일 가지고 잇음???
근데 만약에 파일을 통으로 하나로 유지해서 있냐 없냐를 물어보는 건 문제가 있음
이러면 한 사람한테 쭈욱 받아야 하는데 피투피 원리에도 안맞고 어렵다.
그래서 어떤 파일이든 잘게 조각을 냄
한 조각을 청크라고 함 대충 256KB
이 파일들이 네이버들에 흩어져 잇음
그러면 자동으로 연결되어있던 애들이 이 파일들을 나한테 보내줌
그렇게 나는 하나의 파일을 완성하는 것임.
그래서 이 매커니즘은
- 트래커가 네이버링을 지정해주는 것
- 파일을 청크라는 작은 조각으로 나눠서 분산해서 왔다갔다 하게 하는 것
- 유저가 참여했다 나갓다 하는게 churn 이라고 것.
프리라이딩 프라블럼
내가 파일을 요청해서 받았어, 그래서 값진 파일을 받았다
그러면 나도 이 파일을 사람들한테 나눠줘야지~~ 해야되는데 자기가 가지고 싶은 파일 얻자마자 나가버림
이러면 피투피가 유지되기 어려움 ⇒ 셀피쉬하다고 함
반대는 알투리스티칼리
이 문제 어떻게 할거임?????????????????????????
이 문제의 해결 전략 : tit-for-tat
눈에는 눈, 이 에는 이,
상대가 나한테 10을 주면 나도 10을 주고, 나한테 도움 안되게 굴면, 나도 도움 안되게 굴기
나한테 잘 주면 나도 잘 주고 나한테 잘 안주면 나도 잘 안줘
처음에 들어갔을 때는 주고 받고 주고 받고 했을 때, 가장 나한테 잘 주는 사람을 네이버링으로 해서 4명 정도를 그룹을 만들어서 집중적으로 관리를 함.
근데 이 4명이 잘 돌아간다고 생각하지만 숨어잇는 더 좋은 짝이 있을 수 있음.
나한테 더 잘 주는!!!!
그래서 랜덤으로 내 짝 중에서 한 명을 버려보고 다른 애를 집어 넣어보고 의외로 더 잘하면 새로운 짝이 되는 것임
이걸 옵티미스칼리 언 초크 라고 함.
엘리스가 밥한테 아무 조건 없이 데이터를 한번 보내줌. 걍 시험 삼아서 해보는 겨.
근데 엘리스가 의외로 보내는걸 잘해 속도도 좋고, 그러면 밥은 엘리스를 자신의 상위 4개 업로더 중에서 하나로 등록함.
그럼 이제 밥도 엘리스한테 데이터를 나눠줌.
이제 밥도 엘리스한테 데이터를 잘 주니까 엘리스도 밥을 자신의 상위 업로더 중 하나로 등록함
서로 파트너 맺은 것!!!
Contents Distribution Network
쉽게 말해서 유튜브, 넷플릭스
지금 인터넷은 대부분 트래픽이 비디오 트래픽임
거의 50퍼 이상
수십억명이 비디오 파일을 요청하는데 어떻게 유지하지???
분산적으로 CDN을 구축
쉽게 말해서 스트리밍 스토어드 비디오 형식으로 하자
파일 자체가 완성되어있고 이걸 서버에 요청해서 파일을 가져옴
이때 필요한 기술이 대쉬 기술
대쉬는 기술 이름!!!!!!!! 프로토콜 아니야!!!!!!!!!!!!!!!
HTTP 프로토콜 위에서 돌아가는 기술 이름
이 대쉬 기술을 이용하면 서버는 수많은 비디오 파일들의 청크를 가지고 있는데, 각각의 청크들을 서로 다르게 (서로 다른 레이트로) 인코딩이 됨.
manifest file: 서로 다른 청크에 대해서 유알엘을 제공해주는 파일
클라이언트가 서버에 접속해서 데이터를 요구할 때 그냥하는게 아니라 서버에서 풀링을 해서 다이나믹하게 네트워크 상태를 점검.
지금 당장 밴드위드 이용가능한지 왔다갔다할때 컨제스쳔은 없었는지 관찰한 다음에 메니페스트 파일이랑 컨설팅함.
“나는 어디서 어떻게 파일을 받아오는게 좋을까요??”
대쉬 기술이 “너는 어느 정도 레이트로 디코딩된 파일을 쓰는 게 좋겠다”
“그리고 서버중에서도 여기 서버에 있는 어느 정도 레이트의 퀄리티를 주는 청크를 가져다가 써라”
클라이언트는 인텔리전트하게 when, what, where 을 결정
언제 접속???
어떤 인코딩 레이트로(동영상의 퀄리티)?????
어떤 서버에서????
이걸 판단하고 연결됨
이제 서버를 찾아가야함.
근데 싱글 라지 메가 서버만 사용한다??? 그럼 문제가 심각함
여기 벤드위드 터져버리면 걍 게임 오버임.
전세계에서의 접속이 먹통이 됨
그리고 컨제스쳔 컨트롤이 나서 데이터 트래픽 너무 복잡해짐
그래서 CDN 을 사용하는 것임.
수 많은 멀티플 서버를 놔두는 것임
전세계에 수많은 사이트에 서버를 분산적으로 많이 설치하자
2가지 기법
- enter deep
- bring home
내가 넷플릭스에 나쁜녀석들 보고 싶다고 서버에 요청을 보냄
메니페스트 파일이 클라이언트의 상황을 고려해서 엔터딥된 곳에서 청크 파일을 받아서 디스플레이 하는 것
Over the top
⇒ OTT
티비 셋이 탑 레벨이라 생각햇는데 그 위에 탑이 더 잇다 오버 더 탑
인터넷을 통해서 우리가 보고싶은 동영상의 정보를 받아서 보는 것
밥이라는 애가 영화를 보고 싶어.
나는 “~~~에서 영화를 OTT로 보고싶어”
“너는 위치가 어디고 어디고 하니까 ###라는 어떤 특정 서버로 가봐라 (메니페스트가 지시)”
근데 ### 라는 이름을 가지고도 수많은 아이피 주소가 존재 (서버가 존재)
그러면 메니페스트는 특정한 아이피를 줬을 거임
근데 특정한 아이피가 어딨는지 몰라서 로컬 DNS 서버에 물어봄
로컬 DNS도 모르면 root DNS 서버에 물어보고, … 오쏘리터티브까지 물어보고 아이피 주소를 찾는 것
이게 CDN 메카니즘
근데 요즘 이것도 어렵다!!!!!!!!!!!1
⇒ AWS, 아마존 웹 서버
이게 넷플릭스랑 계약을 맺어서 넷플릭스 서비스를 아마존 클라우드에서 서비스 함.
처음에 넷플릭스에 가서 물어보면 아마존 클라우드로 가서 특정 CDN 서버 접수 받고 보여준다.
Socket Programming with UDP and TCP
소켓: 레이어들은 각자 블랙박스되어있는데, AL에서 TL 통신할 때 사용하는 출입구 같은 것
소켓이라는 함수를 불러서 다음 레이어로 이동하는 것
예를 들어서 두 엔드 시스템이 프로세스를 어플리케이션에서 돌리고 있다고 치자.
얘네들은 물리적으로 떨어져 있는데, 완전히 다른데, 직접 매핑 되어있다고 생각함.
여기서 요구 사항을 보낼 때 실제로 1대1로 가는게 아니라 아래로 내보내는데, 문 역할을 하는 게 소켓이다.
UDP: unreliable datagram protocol : 믿을만 하지 않다
TCP: transmission control protocol (reliable) : 믿을만하다
내가 패킷을 보내면 100퍼 가도록 보장해야함 (TCP)
UDP는 아님. 열심히 할게요! 근데 책임은 못진다 마인드
socket with UDP
unreliable = no connection
보내는 쪽과 받는 쪽의 고정된 루트를 확보하지 않고 걍 보냄. 뒷감당 없어
걍 보냄
그래서 데이터가 중간에 로스트되거나 아웃 오브 오더 되어도 노 상관
TCP는 순서를 직접 맞춤. 1번오면 2번이 와야함 2번 오면 3번이 와야하고
근데 UDP는 이걸 안함. 그럼 순서 개판됨?? ㄴㄴ
얘는 이걸 어플리케이션 레이어에서 이거 순서를 맞춤
UDP로 소켓 프로그램을 짜면 서버는 서버 쪽에 프로그램이 있고 클라이언트는 클라이언트에 프로그램이 있음
소켓 함수로 문을 열어서 특정 데이터를 보낸다면 서버는 소켓 프로그램으로 데이터를 기다리면서 어떤 자료가 오면 어플리케이션 레이어에 올리고 데이터를 바꾼 다음에 다시 보내줌.
socket with TCP
먼저 서버랑 컨택함
걍 막 보내는게 아니라 서버쪽에서 확인이 필요함
“그래 너가 연결을 원하는 구나, 포트 번호 정해줄테니까 여기로 와라” ⇒ 커넥션
그러면 이걸로 데이터가 왔다 갔다.
패킷들이 쭉 들어오면 순서를 맞춰줌
오더링을 알아서 해줌
그리거 나서 완성된 파일이 어플리케이션 레이어로 올라감
서버쪽에서 소켓을 열고 기다림
그 다음에 클라이언트도 소켓을 열고 커넥션이 일어남
이때는 TCP 커넥션이 일어남 (3웨이 핸드셰이킹)
그 다음에 데이터를 보내는 것.
'지식 > 컴퓨터네트워크' 카테고리의 다른 글
| Network layer (0) | 2025.04.25 |
|---|---|
| Transport layer (0) | 2025.04.25 |
| Introduction (2) | 2025.04.25 |


