Transport-layer services
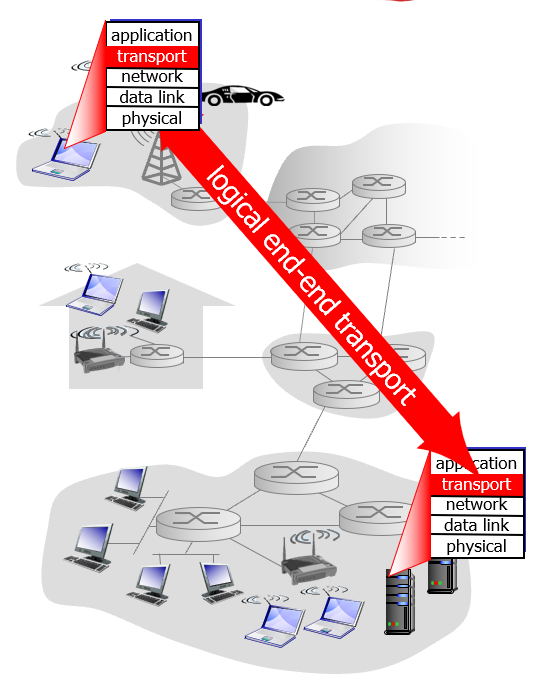
트랜스포트 레이어는 서로 다른 호스트 간에 수 많은 멀티 홉 거치는게 아니라 로지컬하게 다이렉트로 연결된거 같이 느끼도록 하는 서비스를 제공함.
(블랙박스로 보면)
AL의 데이터 단위를 메세지라고 함.
메세지는 AL 에서 생성된 데이터의 페이로드임.
TL로 오면 이걸 잘게 작작작 쪼갬.
AL에서 온 데이터는 큰 덩어리임.
(일정한 크기로 잘라짐)
잘라지면서 여기에 헤더 파일이 붙음.
이 헤더 파일에는 포트 정보 같은데 들어감.
잘게 쪼개진 데이터 단위를 세그맨트라고함
이 세그먼트가 NL로 또 내려감.
그러면 여기에도 헤더 파일이 붙는데, 여기에는 아이피 정보가 들어감.
그래서 만들어진 새로운 정보 단위를 데이터 그램이라고 함
정보가 destination까지 가면 정보가 역으로 올라감 NL → TL → AL
올라갈때마다 헤더 파일 하나씩 지우면서 올라감.
TL에는 굉장히 중요한 프로토콜이 돌아감
- TCP
- UDP
그러면 밑에 있는 NL은?
사실 NL은 호스트와 호스트를 로지컬리 다이렉트하게 연결된 것처럼 느끼게 해줌. (방금전까지 트랜스 포트 레이어라고 했지만… ㅋ)
크게 생각해보자.
밑에 레이어들은 위에 있는 레이어를 지지하는 레이어임
AL에서 어플리케이션(프로세스)이 돌아가고, TL에서는 이걸 지지해야되니까 프로세스들 간의 소통을 담당함.
NL은 또 이걸 지지해야되니까 호스트 간의 소통을 담당함. (그리고 NL은 상대방의 아이피를 알고 있으니까)
TCP
reliable, in-order
100퍼 패킷 도착을 보장, 전송이 실패해도 적당히 전달하는 방식은 없음
내가 보내는 패킷들 중에서 하나라도 뻑나면 실패로 생각하고 다시 보냄.
컨제스쳔 컨트롤, 플로우 컨트롤, 커넥션 셋업도 다 해줌
커넥션 셋업
커넥션 셋업은 미리 핸드 쉐이킹해서 커넥션을 만들고 끝나면 제거해주는 것.
컨제스쳔 컨트롤
컨제스쳔 컨트롤은 어렵고 잘 안됨.
인터넷 같이 복잡한 상황 속에서 이걸 제어하는게 쉽지 않음.
우리도 어디서 뭐가 어떻게 되는지 완전하게 모두 파악하기가 어려움.
예를 들어서 유독 7번 라우터에서 컨제스쳔이 발생했다고 치자, 근데 컨제스쳔이 일어났을 때, 원인이 어디에 있는지 파악하기 어려움.
혼잡이 일어났다면, 어느 구간에서 혼잡이 일어나는건 알겠는데, 나 혼자 한다고 해결되지 않음. 주위 상황도 관여해서 나 혼자만 해결한다고 되는게 아님.
플로우 컨트롤
받아 들이는 녀석의 캐패시티를 고려해서 패킷을 조절하는 것
UDP
no-frills
레이스가 많이 달린 장식
위에 있던 정교한 기술이 없는 best-effort 걍 최선만 다하는 놈!
근데 위에 두 프로토콜을 딜레이, 밴드위드가 개런티가 안됨.
Multiplexing and demultiplexing
Multiplexing
멀티플렉싱은 쉽게 말해서 내가 보내는 거를 쭉 나눠서 보내는 것
소켓을 통해서 AL 에서 데이터가 들어오면 이 데이터의 헤더 파일을 보고 어디로 갈지 쭉 나눠주는 것.
AL에서 수많은 프로세스가 있는데 이 녀석들이 수 많은 소켓을 열어서 메시지들을 내보냄.
그러면 TL에서 수 많은 세그먼트들이 만들어지는데,이걸 NL로 보내고 NL은 이걸 분배해서 보내는 것.
너는 일로, 너는 절로, 너는 교회로
Demultiplexing
쭉 들어오는게 있으면 이걸 받아서 다시 분배하는 것
받는 쪽에서 데이터가 들어오면 이 녀석의 소스와 목적지 IP, 포트 번호를 보고 각자 프로세스를 할당함.
분배가 된 녀석은 IP와 포트 번호를 찾아서 호스트를 찾아서 프로세스까지 찾아감.
How demultiplexing works

TCP, UDP는 실제 data payload가 있고, 여기에 헤더 파일을 붙여줌.
여기서 외워야할 것은 헤더 파일에 src와 dest의 포트번호가 있다는 것!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
datagram은 NL의 데이터
datagram은 TL로 올라가려면 IP주소가 필요함.
이 아이피로 호스트를 찾음.
그리고 TL에선 segment인데, 여기에서 포트번호 보고 AL로 올라감. 적절한 소켓을 통해서~
Connectionless demux: example
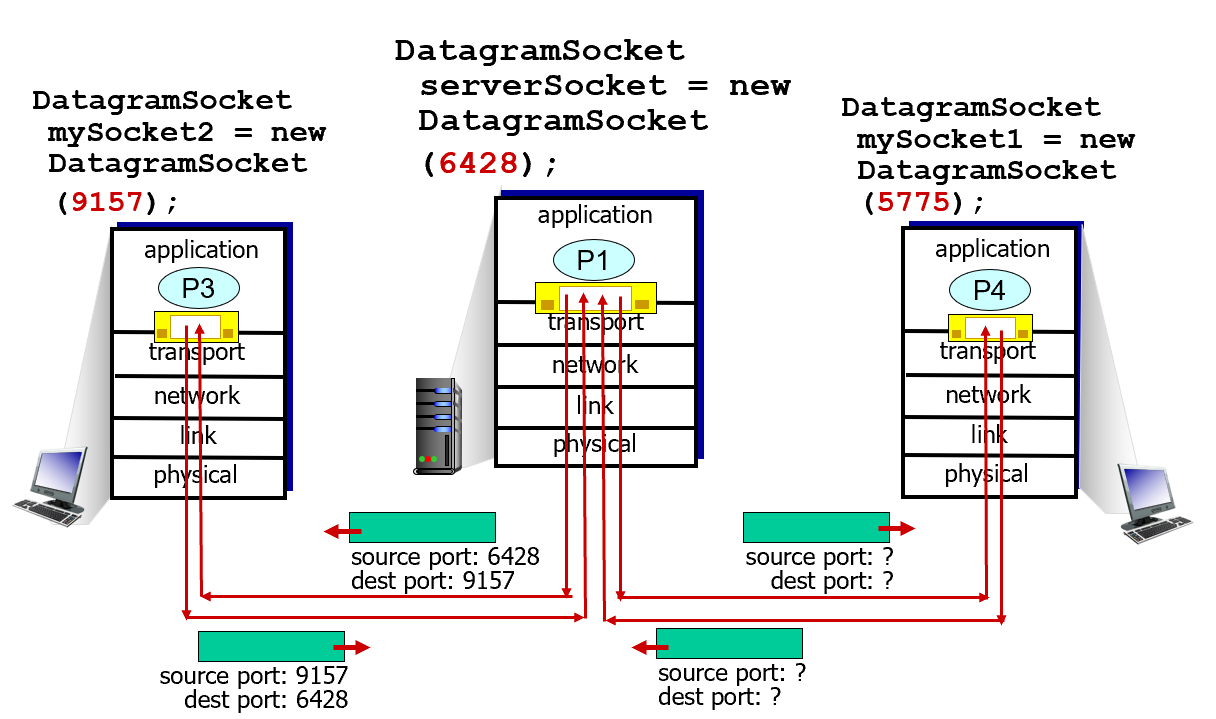
UDP 방식
처음에 호스트에서 프로세스가 소켓을 열어서 메시지를 TL로 내보냄.
AL에서 프로세스가 소켓을 열 때, 포트번호가 정해짐.
TL은 이거 받아서 짝짝짝 쪼개서 각각 헤더 파일 붙이고 src와 dest의 포트번호 붙여서 세그먼트를 만듦.
이걸 NL로 보냄
NL은 여기에 아이피 들어있는 헤더 파일 하나 더 붙여서 보냄.
이 녀석이 destination 갈 때는 거꾸로 해서 올라감.
NL에서 IP 보고 얘가 일로 오는 걸 알 수 있음
TL에서는 포트 번호 보고 어떤 소켓으로 갈지 결정함.
AL은 받은 녀석을 프로세스에서 사용
나한테 오는 클라이언트들의 src IP, src port number 다 쌩까고 무조건 dest port numer 만 보고 이게 같은 녀석을을 하나의 소켓으로 싹 다 받
위 예시를 통해서 알아보자
현재 p3과 p4이라는 클라이언트가 p1이라는 서버와 소통하고 싶어한다.
먼저 p3는 AL에서 메시지 만들고 소켓 열어서 TL로 내려옴.
TL에서는 이걸로 세그먼트를 만드는데, 여기에는 헤더(src port, dest port)와 페이로드(actual data)가 담겨있음.
포트 정보가 p3의 포트(src port)와 p1의 포트(dest port)인 것!
그 다음에 서버까지 도달하려면 dest IP address가 필요한데 이건 NL에서 데이터 그램이라는 녀석의 헤더 안에 존재한다.
p4에서도 위 과정을 똑같이 따를 것임. 근데 src port만 다르고 dest port는 다 같을 것임
현재 그림을 보면 src가 어디던 간에 dest port만 같으면 다 같은 소켓으로 들어오는 것을 알 수 있는데, 이게 뭘 의미하냐면 동일한 프로세스로 들어간다는 말임.
UDP를 사용하면 demux는 dest IP, dest port만 써서 src에서 dest의 어떤 소켓으로 들어갈지 특정함.
Connection-oriented demux
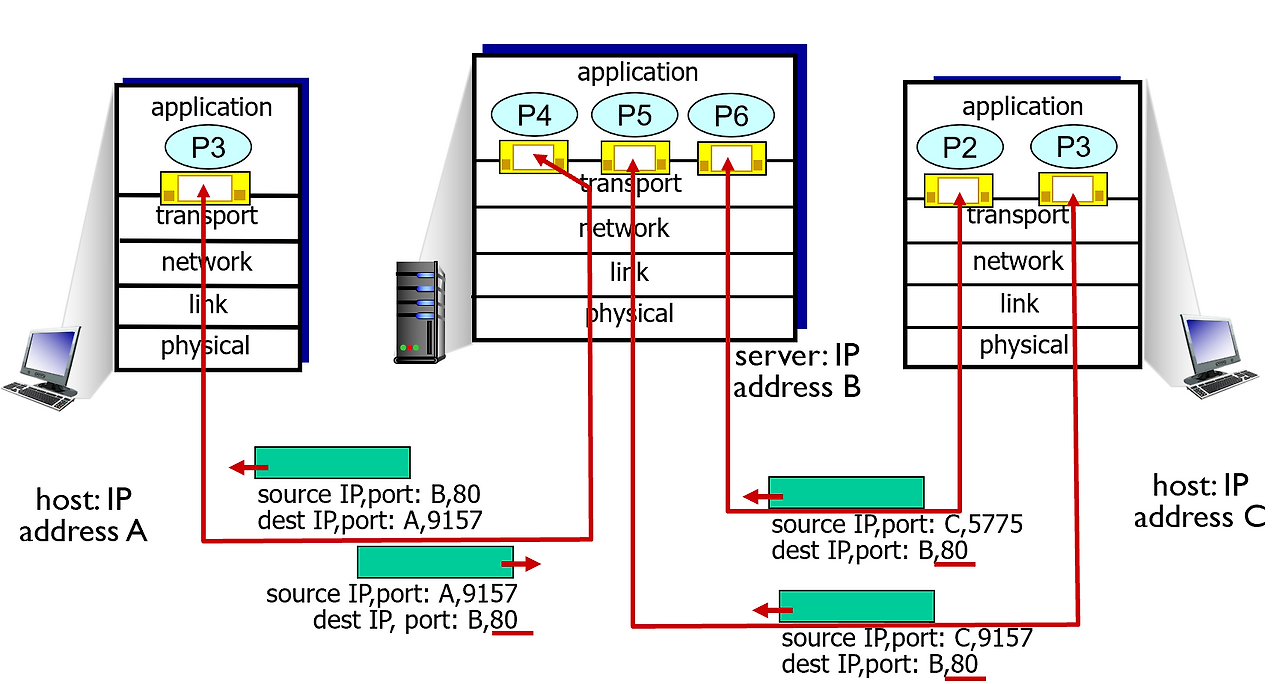
TCP를 사용할 때는 4가지 튜플을 가지고 이게 dest의 어느 소켓으로 가는지 확정함
- src IP address
- src port number
- dest IP address
- dest port number
받는 쪽에서는 이 4가지 튜플을 조합해서 얘가 정확히 어느 소켓으로 들어가는지 TCP가 알려줌
서버와 호스트는 TCP를 열 때 하나의 어플리케이션에서 동시에 수 많은 소켓을 동시에 열 수 있는데, 이러면 좀 복잡해진다.
프로세스에서 소켓이 동시에 여러 개 열리면 어디로 가야 할 지 특정하기 힘든데, 이 4가지 조합하면 쉽게 찾을 수 있는 것.
각각의 클라이언트에 하나의 클라이언트한테 보내는데도 여러 개의 소켓을 열 수 있음
→ Non-persistent HTTP protocol
얘가 예전에 보면 요청 하나 당 TCP 연결을 만들고 응답 받고 이랬음.
그래서 이거는 병렬 처리를 했었는데, 그때 서버가 connection-oriented demux를 통해서 동시 요청들을 병렬적으로 처리했음.
서버는 각각의 연결을 식별해야 되니까!
UDP: User Datagram Protocol
TL의 프로토콜
TCP랑 다르게 no frills! bare bones! 미사어구 없이 기본적인 것만 가진 녀석
best effort
이 녀석은 패킷 로스를 신경쓰지 않음
근데 패킷 도착이 뒤죽박죽이어도 노케어
UDP는 그냥 이걸 dest의 AL로 걍 올려
그러면 AL에서 순서를 맞춤
connectionless = no handshaking
전송해도 됩니까? → ㅇㅇ 전송하셈 → 보내겠슴다 → 다 보냈고 끊겠습니다
위 과정이 없고 걍 보내버림.
UDP는 어따 씀?
문서의 무결성이 중요하면 전부 다 TCP임
SNMP : 심플 네트워크 메니지 먼트 프로토콜, 이게 UDP로 구현
DNS도 UDP로!!
UDP에서 reliability를 줄 수 있음
AL에서 이걸 떠맡아서 하면 됨
AL에서 패킷 로스가 일어나면 다시 요청하고, 아웃 오브 오더면 그걸 다시 오더링을 맞추고,
UDP: segment header
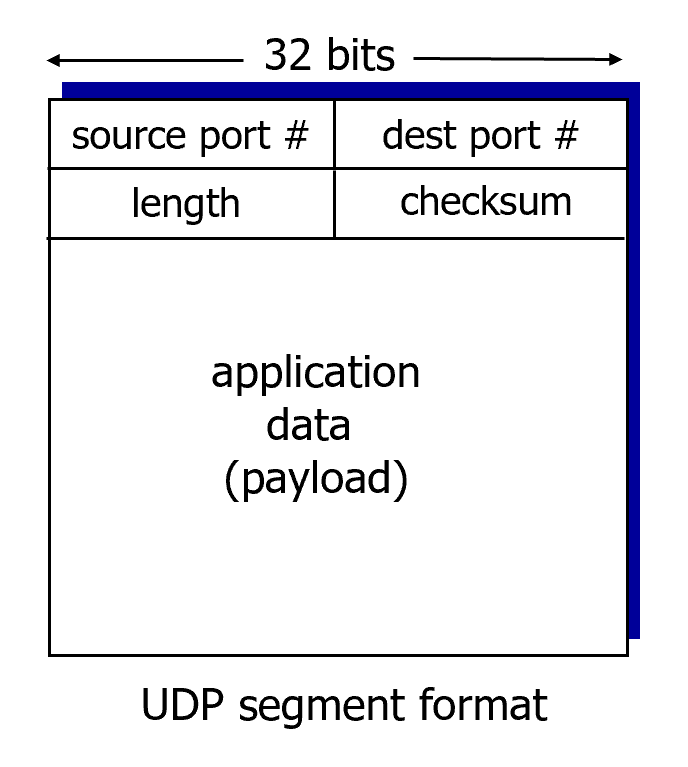
앞에 src와 dest의 port 가 있다~
왜 UDP씀?
- no connection (연결 시간 없음, 딜레이 감소)
- 간단하다 (심플 이즈 베스트)
- TCP에 비해서 헤더 사이즈가 더 적음
- no congestion control
UDP checksum
UDP 프로토콜에서 사용하는 에러 체크 기법
체크섬은 받는 쪽이 패킷이 도착했을 떄 에러가 없이 잘 왔을 지 체크 하는 것
“여기에 혹시 플립 비트가 있지 않을라나??”
Principles of reliable data Transfer
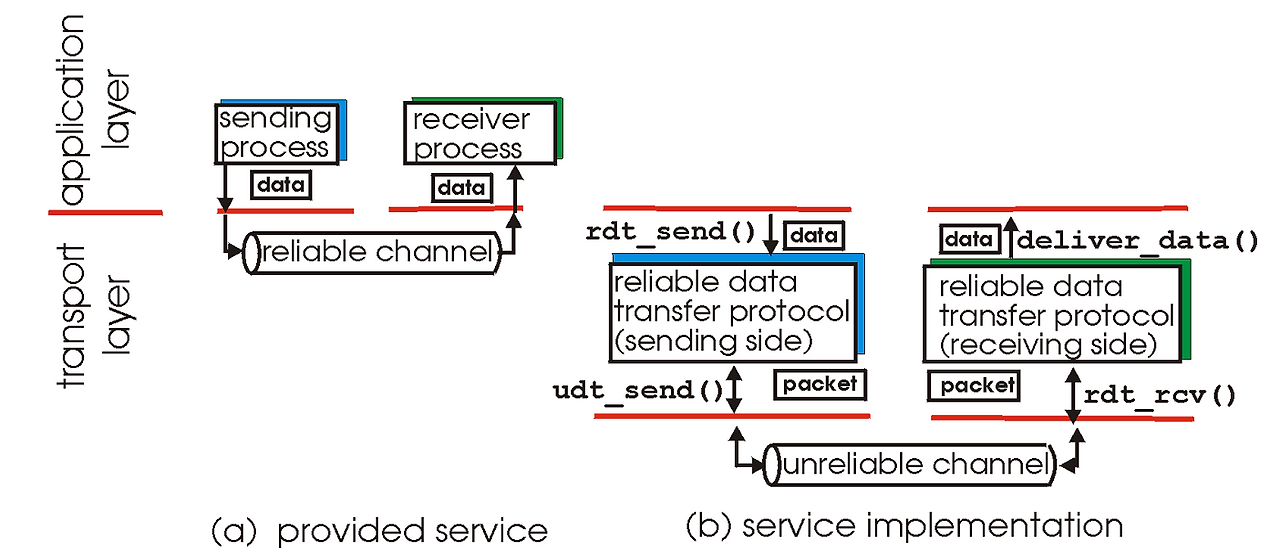
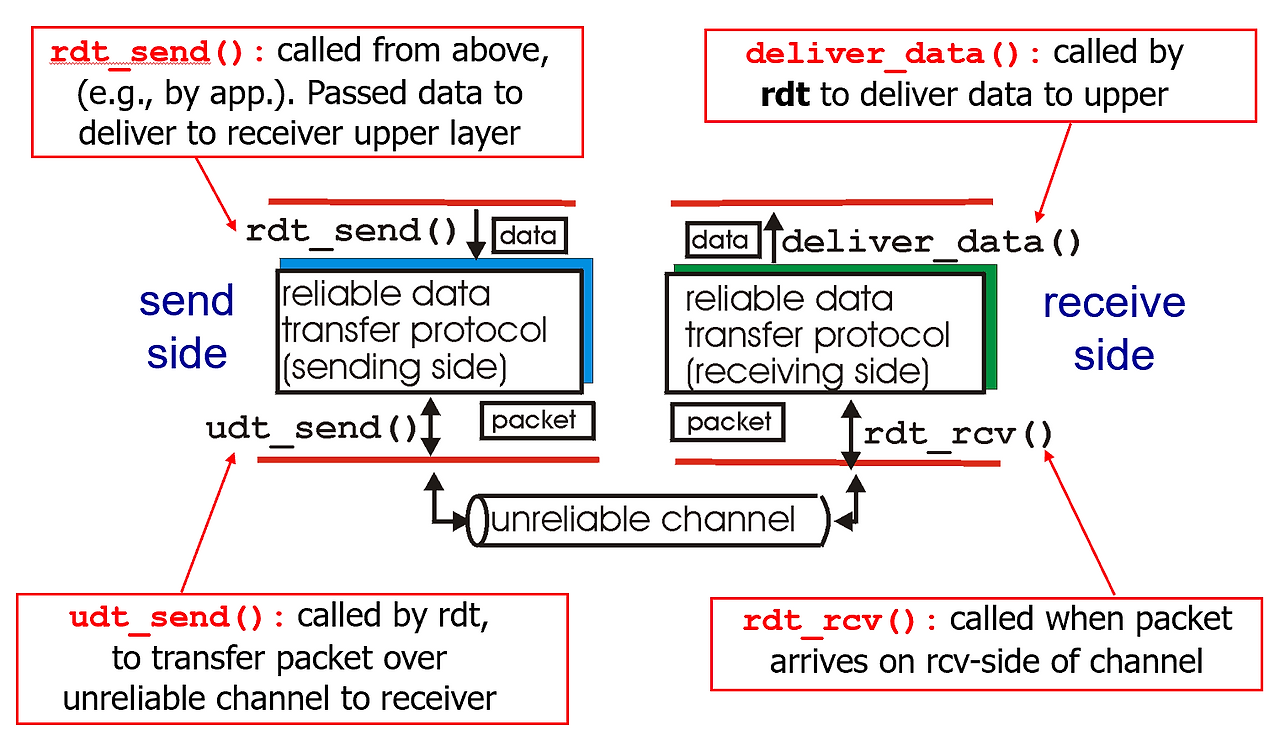
데이터를 보내는데, reliability를 보장하면서 보내는걸 reliable data transfer (rdt)라고 함.
RDT는 실제로 데이터가 손실되거나 손상 될 수 있는 네트워크 환경에서도 정확하게 릴라이어블하게 데이터를 전달하기 위한 전송 프로토콜 같은 것이다. 실제 프로토콜은 아님.
실제 네트워크에서 NL 계층이 언릴라이어블하기 때문에, 데이터 그램이 중간에 손실되거나 중복되거나, 순서가 뒤바뀔 수 있다. 이런 문제를 해결하기 위해서 TCP와 같은 TL은 RDT 매커니즘을 도입하는 것이다.
RDT는 센더에서는 AL에서부터 받은 메시지로 세그먼트를 구성하고 시퀀스 번호랑 체크섬을 넣어서 NL로 전송한다.
dest 쪽에서는 이 데이터를 받아서 체크섬으로 손상 검사하고, 시퀀스 번호로 중복 제거랑 순서를 오더링함.
만약에 손상되거나 누락된 데이터가 있으면 dest쪽에서 ACK이나 NACK을 보냄. 재전송은 센더에 따라서 결정 (rdt 3.0 부터 타이머)
이 과정에서 TL 아래는 언릴라이어블 하지만 TCP가 위에서 릴라이어빌리티를 보장하는 역할을 한다.
걍 결론적으로 TCP는 IP위에서 동작하면서 손상 감지, 재전송, 종복 제거, 오더링, 컨트롤 플로우, 컨제스쳔 플로우, … 이런 기능들을 써서 릴라이어빌리티를 보장한다.
언릴라이어블한 네트워크에서 릴라이어빌리티를 만들어내는 마법⭐
rdt 1.0
일단 몇 가지 가정하고 시작함
- 패킷 손상 ❌
- 패킷 손실 ❌
- 순서 뒤죽박죽 ❌
걍 네트워크는 비트 하나도 안틀리게 정확하게 전달해 준다는 것
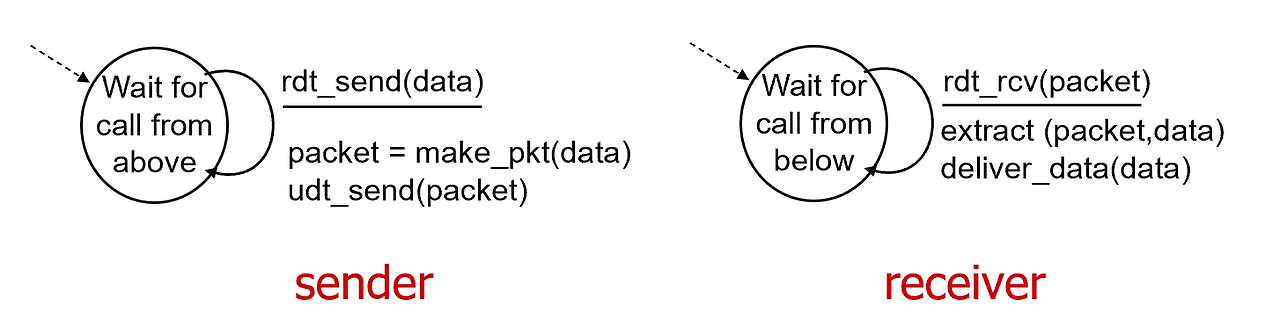
sender
AL에서 rdt_send(data)를 호출함
TL에서는 데이터를 packet으로 만들고 udt_send(packet)로 만들고 NL로 보냄
receiver
packet이 도착하면 rdt_rcv(packet)을 호출함.
extract(packet, data)를 호출해서 데이터를 골라낸 다음에 AL로 deliver_data(data) 해서 보냄
이건 애초에 reliability가 문제가 없으니까 진짜 걍 플로우가 단순함. 에러가 없는 상황이니까
rdt 2.0
rdt 1.0 + 에러 체크 + 에러 극복
패킷에 에러있는 걸 체크하자 (체크섬 사용)
에러가 있으면 에러도 극복할 수 있는 프로토콜을 만들자! ⇒ rdt 2.0
에러 발생하면 다시 보내도록!!!!
다시 보내는건 어떻게???
신호를 보내면 됨 ⇒ ACK, NACK
패킷을 받을 때마다 체크섬을 통해서 제대로 받았으면 ACK 신호를 sender로 보냄
문제가 있으면 NACK 신호를 sender로 보냄
이렇게 에러 디텍션이 가능해짐
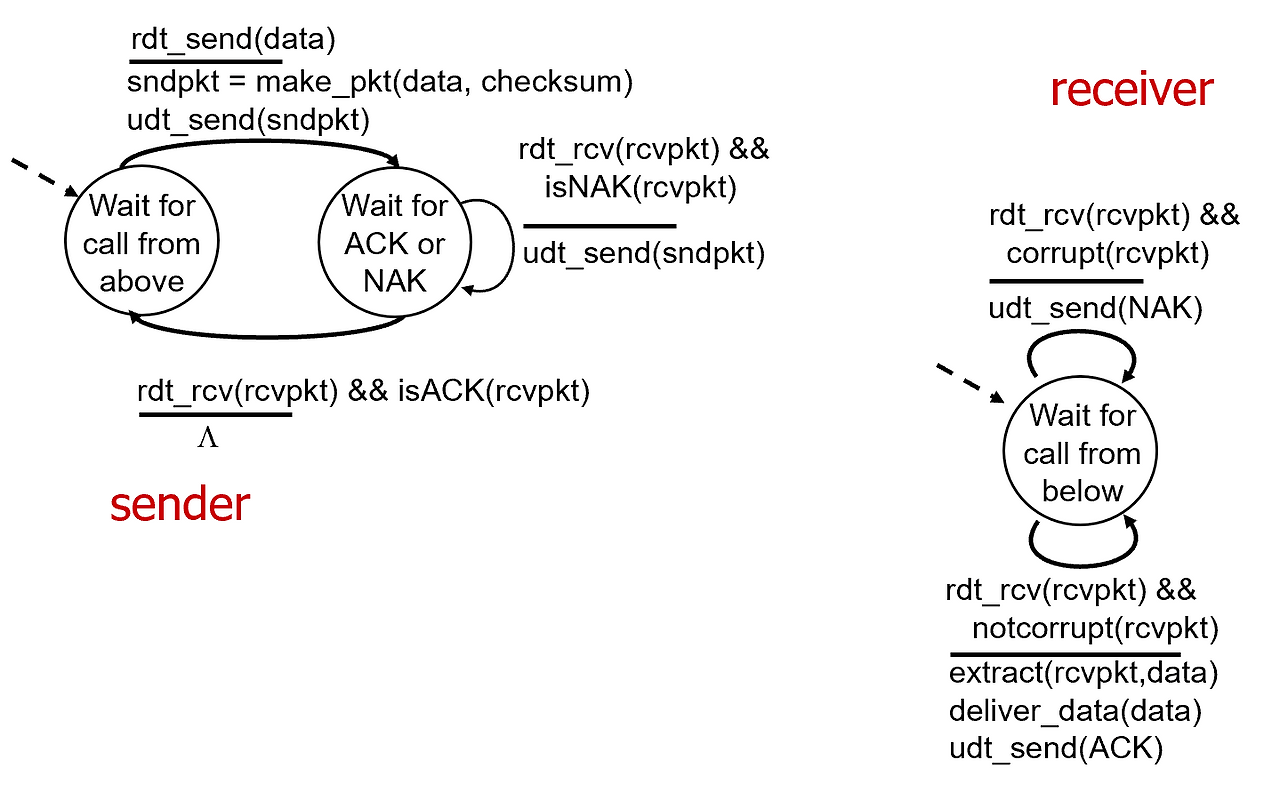
- AL에서 메시지가 내려왔다 → 이걸 체크섬 넣어서 세그먼트로 만들고 리시버로 보낸다 → 나는 ACK이나 NACK wait 한다 → 리시버에 세그먼트가 도착했다 → 체크섬으로 에러 검사 한다 → 문제 없다 → ACK을 센더로 보낸다 → 센더는 ACK이니까 다시 AL에서 메시지 내려오길 기다리는 상태로 wait한다.
- AL에서 메시지가 내려왔다 → 이걸 체크섬 넣어서 세그먼트로 만들고 리시버로 보낸다 → 나는 ACK이나 NACK wait 한다 → 리시버에 세그먼트가 도착했다 → 체크섬으로 에러 검사 한다 → 문제 있다 → NACK을 센더로 보낸다 → 센더는 NACK을 받았으니까 세그먼트를 다시 보낸다 → (반복)
fatal flaws
- 센더가 패킷을 보내고 리시버가 ACK을 보냄
- 근데 ACK이 손상됨
- 센더는 손상되었으니까 다시 패킷을 보냄
- 사실 리시버는 받긴 제대로 받았는데 또 똑같은걸 보내니까 문제가 됨
해결은 시퀀스 넘버를 붙여줘서 해결!
rdt 2.1
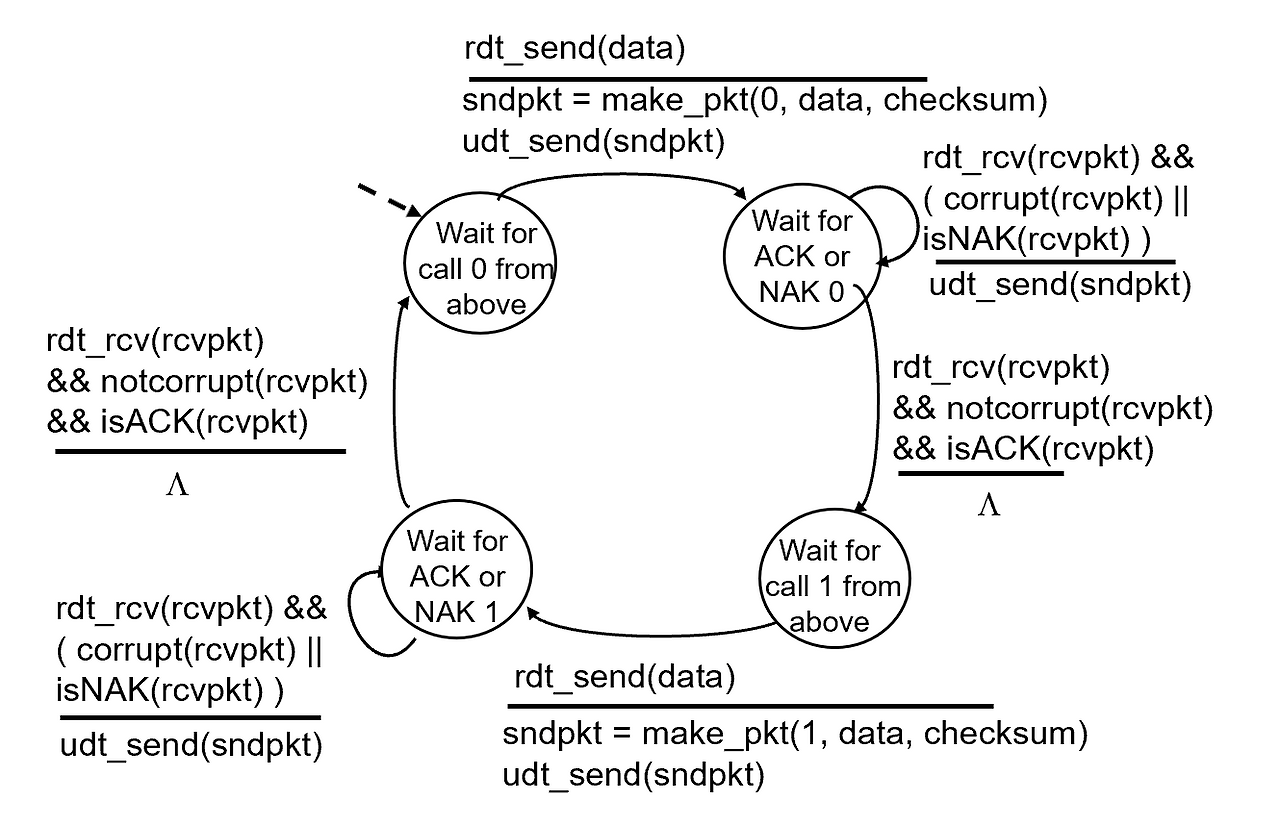
rdt 2.0에서는 문제가 뭐였냐면, 리시버가 데이터를 잘 받았다는 의미로 센더에 ACK을 보냈는데 이게 손상되면, 센더는 ACK이던 NAK이던 신호를 잘못받으면 해당 패킷을 또 보내고 리시버는 이걸 또 받아서 데이터의 중복이 발생하는 거였음.
근데 시퀀스 넘버를 도입해서 해당 신호에 대한 넘버링을 두면 데이터의 중복 수신을 막을 수 있다.
예를 들어서 센더가 시퀀스 넘버가 0인 데이터를 보냈고 리시버가 이걸 잘 받았다고 하자.
그러면 리시버는 잘 받았다는 의미로 ACK을 보낼거임.
만약에 이 신호가 손상되면 센더는 실패한 전송인 시퀀스 넘버가 0인 패킷을 다시 보냄.
리시버에서는 새로 들어온 녀석의 시퀀스 넘버가 1이길 기대함(시퀀스 넘버가 0인건 리시버 입장에서는 잘 받았으니까) 근데, 센더는 시퀀스 넘버가 0인걸 보냄.
그러면 리시버는 데이터가 중복되었다고 판단하고 시퀀스 넘버가 0인 녀석의 ACK을 다시 센더에 보냄.
(시퀀스 넘버는 헤더 파일에 들어감)
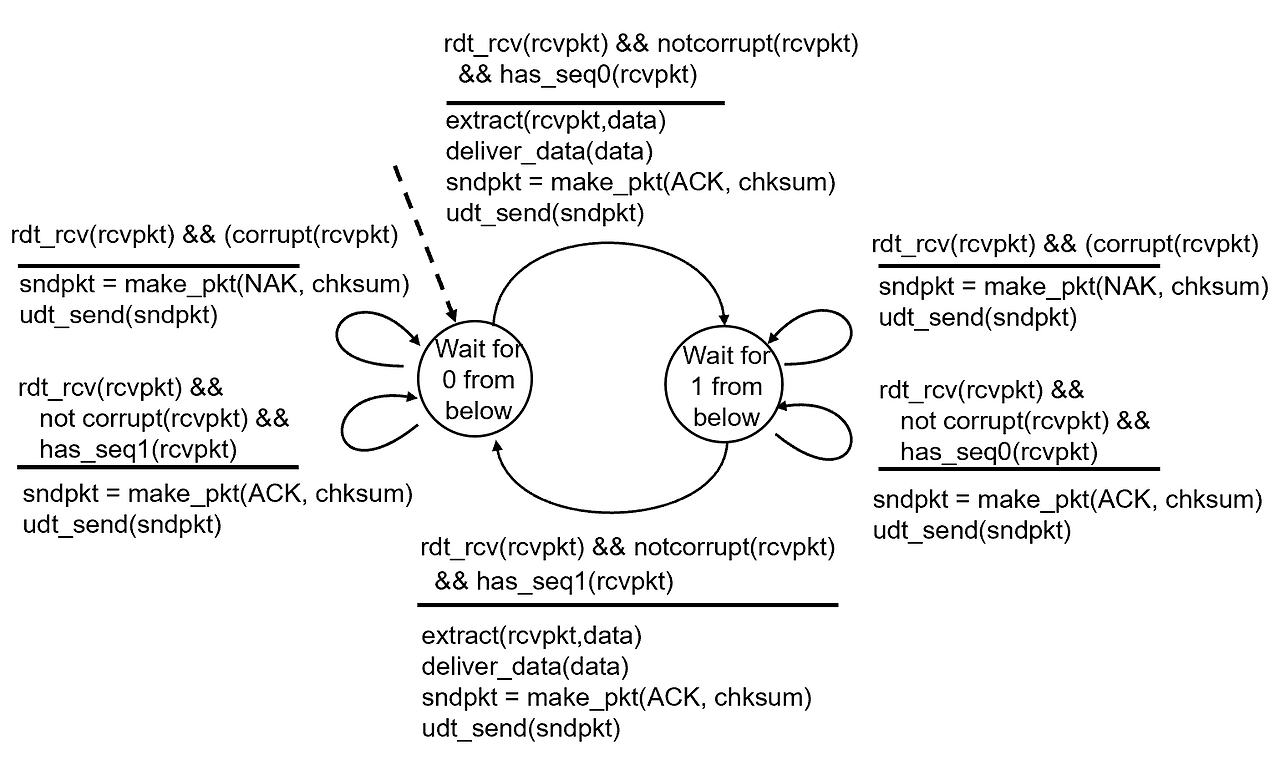
rdt 2.2
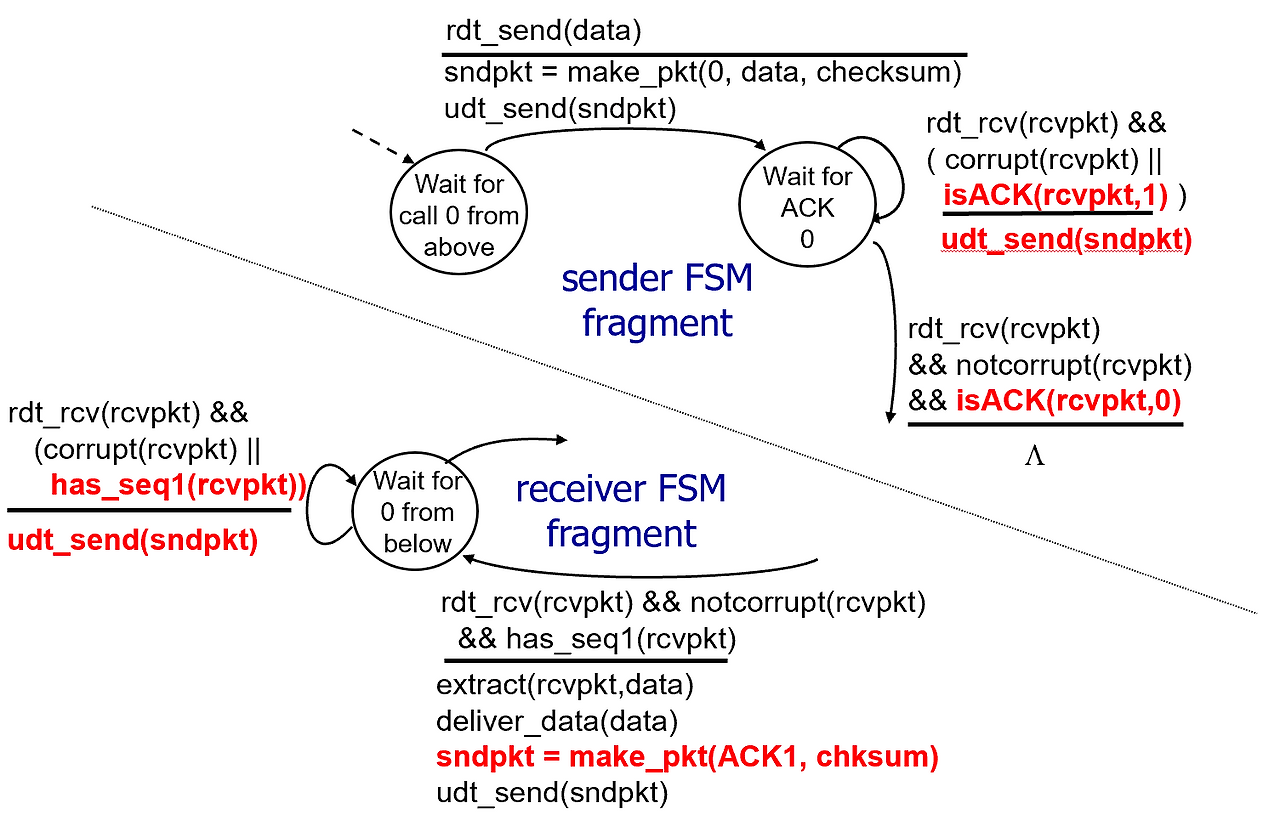
근데 잘 생각해보면 {ACK,0}, {ACK,1}, {NAK, 0}, {NAK, 1} 이렇게 총 4개가 가능한데,
NAK 신호가 굳이 필요하지 않아 보임.
재전송 유발은 시퀀스 넘버만 달라도 가능하니까.
예를 들어서 내가 시퀀스 넘버가 0인 패킷을 보냈음. 리시버는 잘 받았으면 나한테 {ACK, 0}을 보내야 함.
만약에 이게 센더한테 오다가 손상당하면 이전과 같은 시나리오로 센더는 다시 시퀀서 넘버가 0인 패킷을 리시버에 보냄. 그리고 나서 리시버는 이미 시퀀스 넘버가 0인건 잘 받았고 시퀀스 넘버가 1인걸 기대했으니까 다시 {ACK, 0}을 센더에 보냄.
근데 만약에 애초에 센더가 시퀀스 넘버가 0인 패킷을 보냈는데 이 패킷이 손상되었으면??
여기서 리시버는 {ACK, 1}을 센더에게 보냄. 그리고 리시버는 아직 시퀀스 넘버가 0인걸 기대하고 있는 상태.
센더는 {ACK, 1}을 받고 이상한걸 느낌. {ACK, 0}이 와야하지만 {ACK, 1}이 온 것을 보고 시퀀스 넘버가 0인 패킷이 전송 실패했다는 것을 알아차림.
여기서 센더는 {ACK, 1}을 다시 보냄.
flaws
rdt 2.2는 패킷 로스를 고려하지 않음
이 녀석은 패킷 로스가 일어나면 센더와 리시버는 무한정으로 기다리게 됨
내가 보냈는데 뻑나면???
rdt 3.0
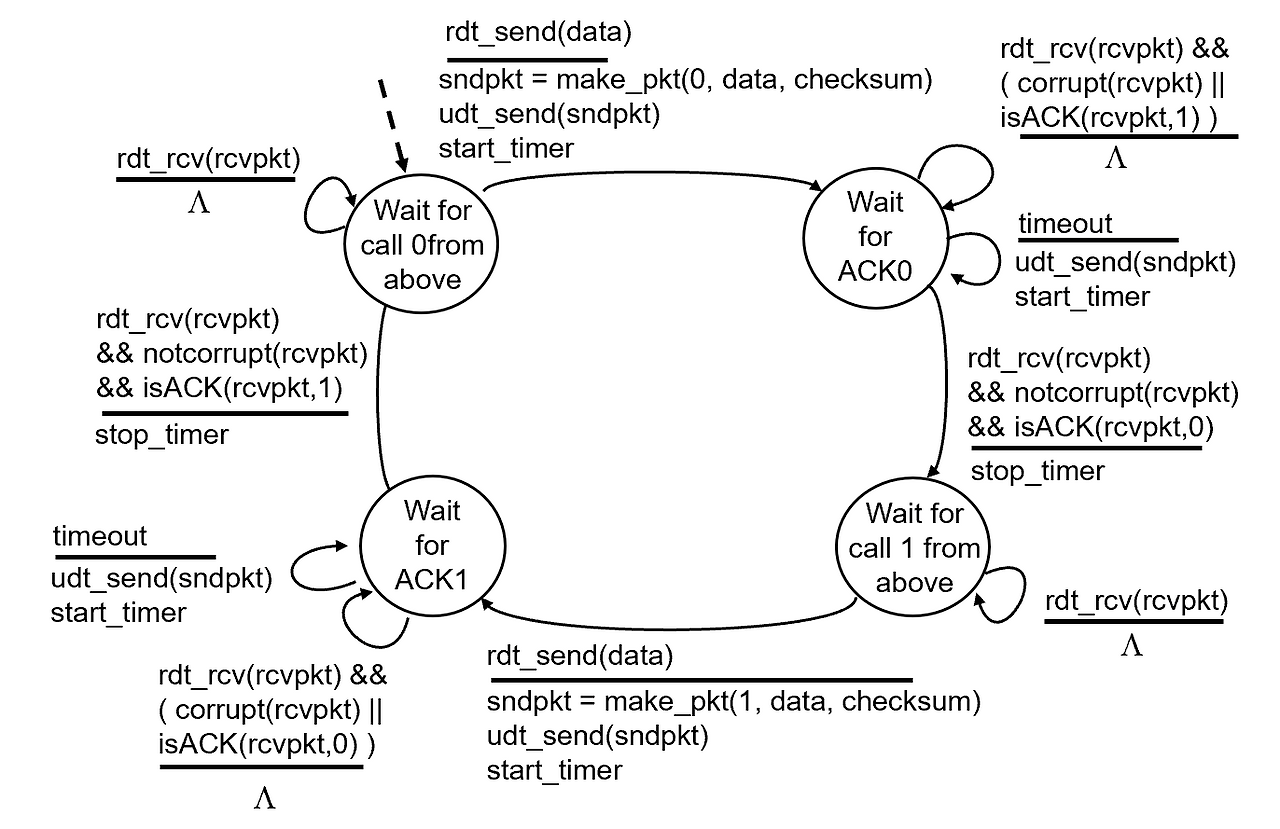
타이머 도입!!!!
보내는 쪽이 ACK 신호를 일정 시간 기다림. 일정 시간 기다리는데 안오면 다시 보냄.
패킷 보낼 때마다 이 짓거리를 반복.
타이머는 센더에 들어감.
센더는 대신 나한테 오는 ACK이 로스된건지 아니면 내가 보낸게 로스된건지 알 수 없음
그거는 알바가 아닌지 또 보냄.
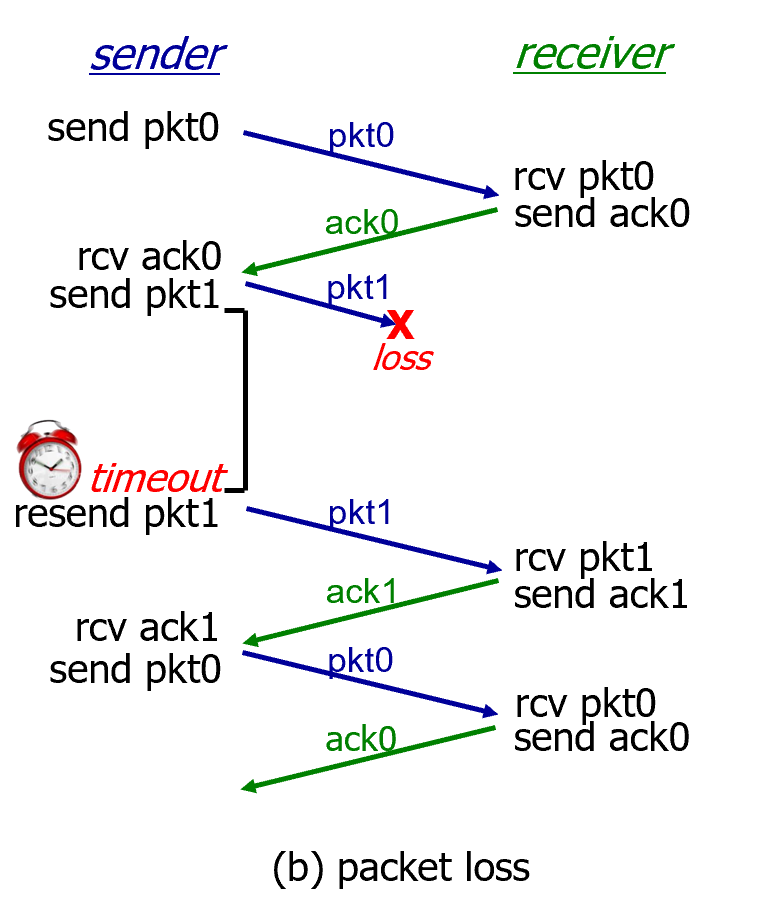
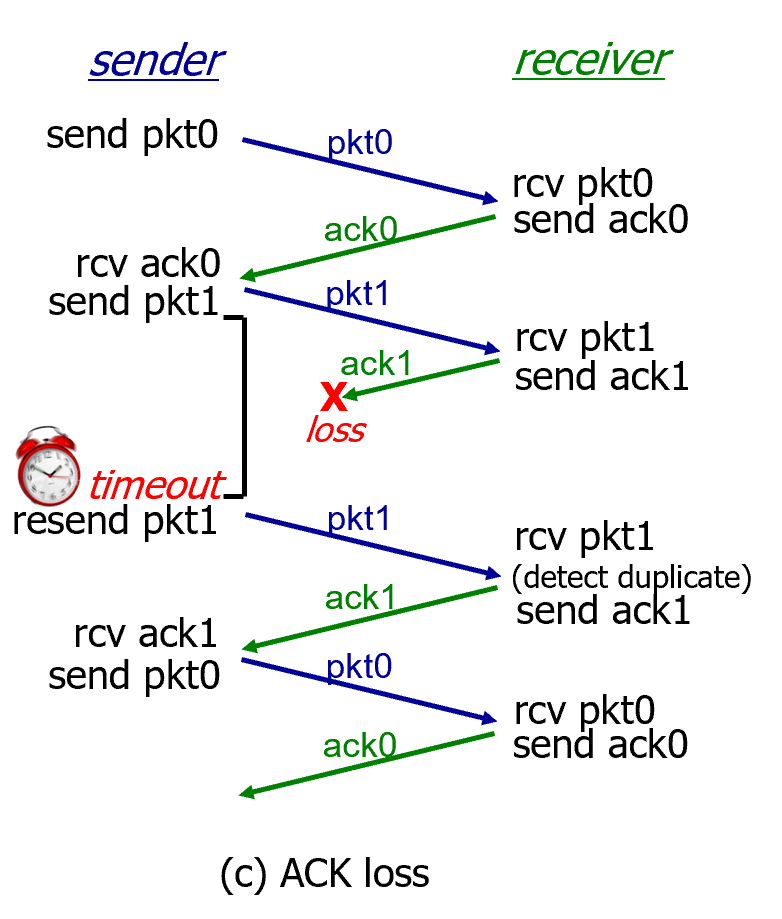
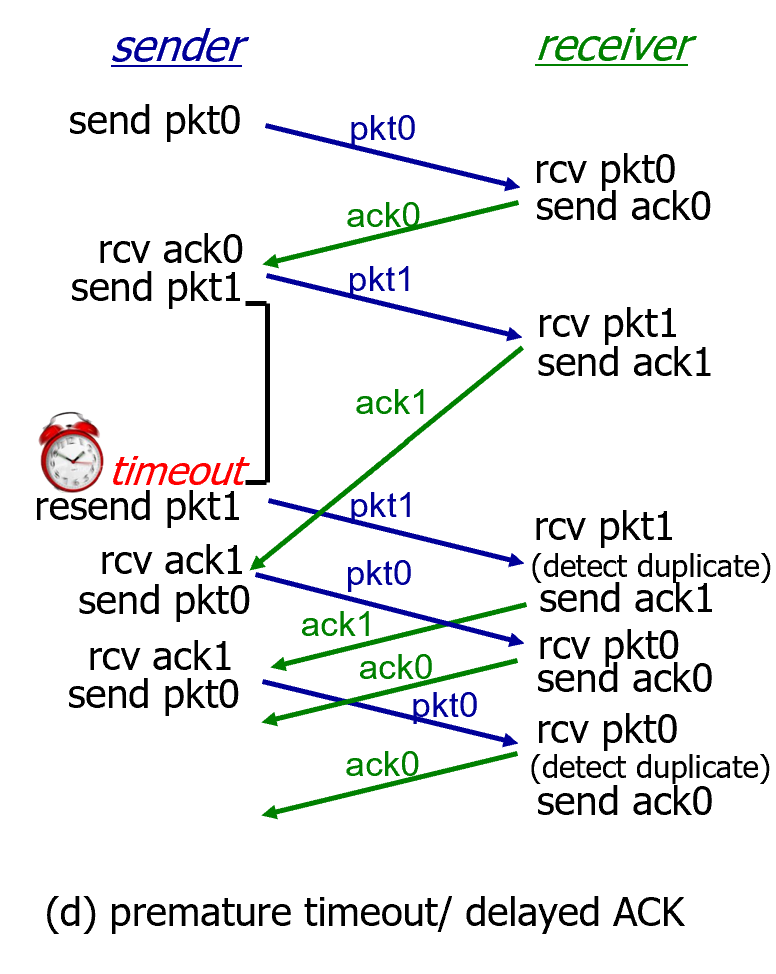
(d)의 경우에는 듀플리케이티드가 엄청 많아져서 오버헤드가 커짐.
Performance of rdt 3.0
퍼포먼스 측정하기 위해서 2가지 방법
- Utilization
- Throughput
Pipelined protocols
센더가 ACK 받는 동안 너무 놀고 있으니까 ACK 안받았어도 일단 packet을 계속 보내 그리고 ACK은 나중에 쭈욱 받아서 확인
그러면 RTT에서 낭비되는 시간 아주 줄일 수 있다.
두 가지 방법
Go-Back-N
이 녀석은 cumulative ACK을 사용함.
내가 만약에 맨 처음에 패킷을 0부터 200까지 보냈다고 치자, 그런데 ACK가 오는데 뜬금없이 ACK 17번이 왔다.
이게 뭘 의미하냐면 17이전의 패킷들을 모두 다 잘 도착했다는 것.
그러면 17만큼 무빙 윈도우가 이동함.
이제부터 18번 부터 무빙 윈도우가 시작하도록 함.
그리고 ACK이 또 오면 그 신호가 cumulative 된 ACK이기 때문에 새로온 ACK 이전 애들은 잘 갔다.
그러면 윈도우도 다시 쭉 밀림.
그리고 ACK이 올 때마다 타임 세팅을 해서 타이머를 설정함.
근데 만약에 아주 운이 나쁘게 무빙 윈도우에 첫번째에 있는 패킷 빼고 다 정상으로 도착했는데 cumulative ACK이라서 ACK 신호가 안와 그래서 타임아웃 기다리다가 싹 다 다시 전송해.
정리
- 리시버는 패킷 로스가 일어난 녀석이 있을 경우, 해당 패킷이 올 때까지 다른 패킷들은 리시버가 받더라도 받지 못한 패킷의 직전 패킷에 대한 ACK을 보낸다.
- 센더는 전송한 패킷 중에서, ACK 되지 않은 가장 최신의 패킷에 대해서 타이머를 젠다
- 리시버는 따로 패킷을 보관할 버퍼가 필요 없음.
- 윈도우 사이즈는 맥스 시퀀스 넘버보다 작거나 같아야한다.
selective repeat
GBN이 문제라서 등장한게 요 녀석
구현 방법은 다른데 핵심 아이디어는 같음
individual ACK, 패킷 하나하나 마다 ACK 신호를 센더가 받음.
3000개를 보내면 3000개에 대한 ACK 신호가 각각 옴.
만약에 맨 마지막거가 날아갔다면 마지막거만 보냄.
대신 ACK 보내는게 오버헤드 있을 수 있음
정리
- 리시버는 ACK이 순서대로 오든가 말든가 걍 받은 패킷에 대해서만 ACK을 보냄
- 센더는 ACK를 받지 못한 모든 패킷에 대해서 타이머를 계산함
- 따로 받은 패킷을 보관할 버퍼가 필요함.
- 윈도우 사이즈는 맥스 시퀀스 넘버의 절반보다 작거나 같아야 한다.
TCP round trip time, timeout
TCP의 timeout 기준을 어떻게 결정하는지?
RTT는 어떻게 측정하나?
⇒ Weighted moving average
EstimateRTT = (1 - a) * EstimateRTT + a * SampleRTT
a는 보통 0.125
sample RTT는 가장 최근에 측정한 RTT
근데 이걸로 RTT를 쓰지 않는다.
+ 유도리 필요
TCP segment structure
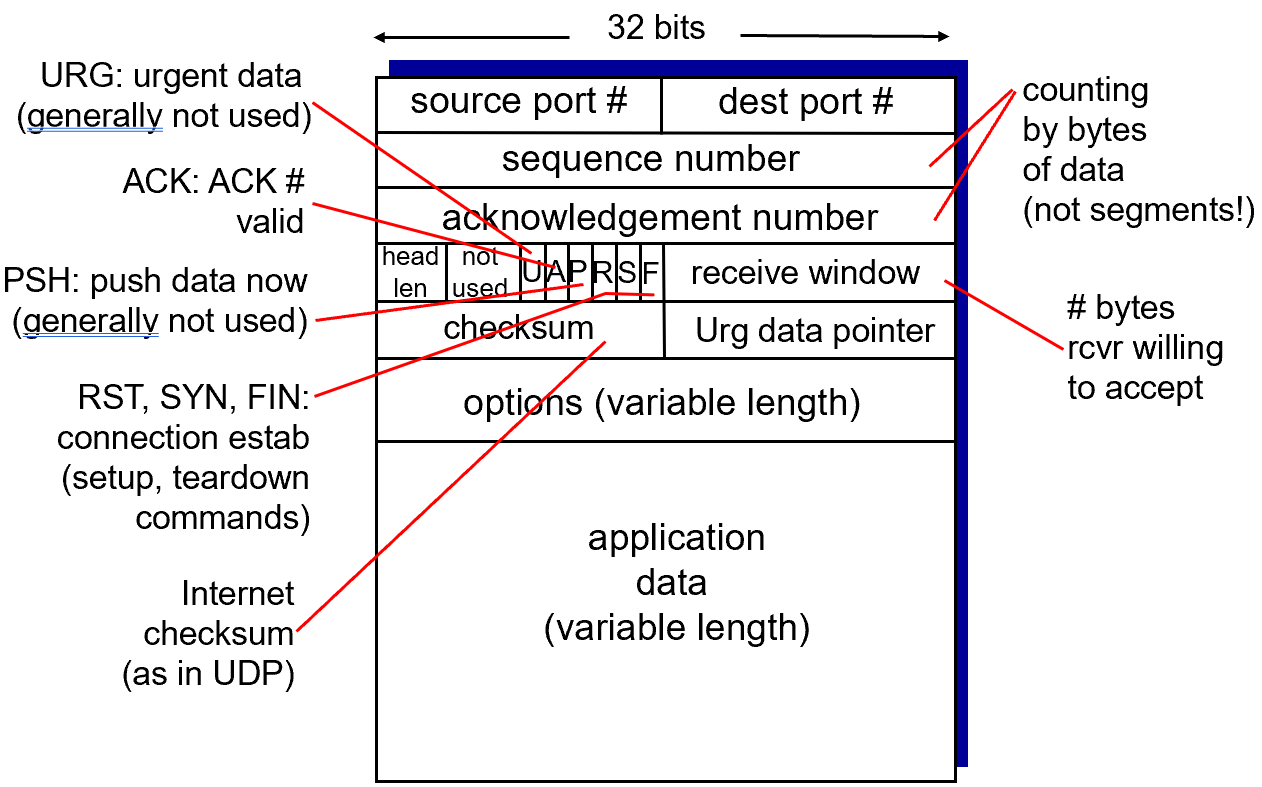
TCP에 헤더 파일이 붙는데 여기에는 포트 번호가 들어간다, 시퀀스 넘버가 있다, ACK 넘버가 있다는 것만 알면 됨.
- 시퀀스 넘버: TCP는 스트림 단위로 정보가 전송되는데, 패킷을 만들 때 지가 임의의로 잘라서 패킷을 만듦. 전체 스트림에서 시작되는 비트의 정보가 시퀀스 넘버
- ACK 넘버: 내가 TCP에서 ACK을 보낼 때 이 신호를 보고 넘버를 찍어줌. 받은 정보가 아니라 기대되는 값.
TCP fast retransmit
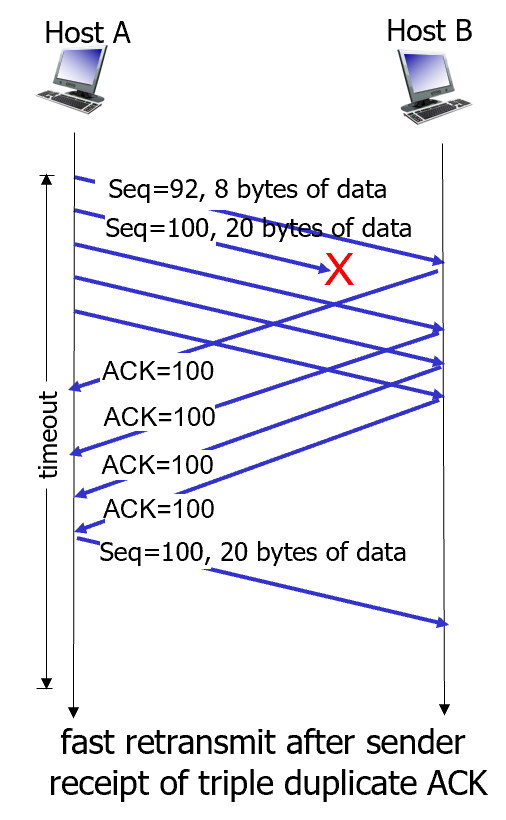
우리가 타임 아웃이 발생하면 센더가 패킷을 다시 전송하도록 하는데, 이거 너무 오래 걸린다.
추가적으로 기준을 정해놓고 이 기준에 부합하면 걍 다시 보내자.
⇒ 중복 ACK이 3번 이상 도착하면 걍 재전송하기
TCP flow control
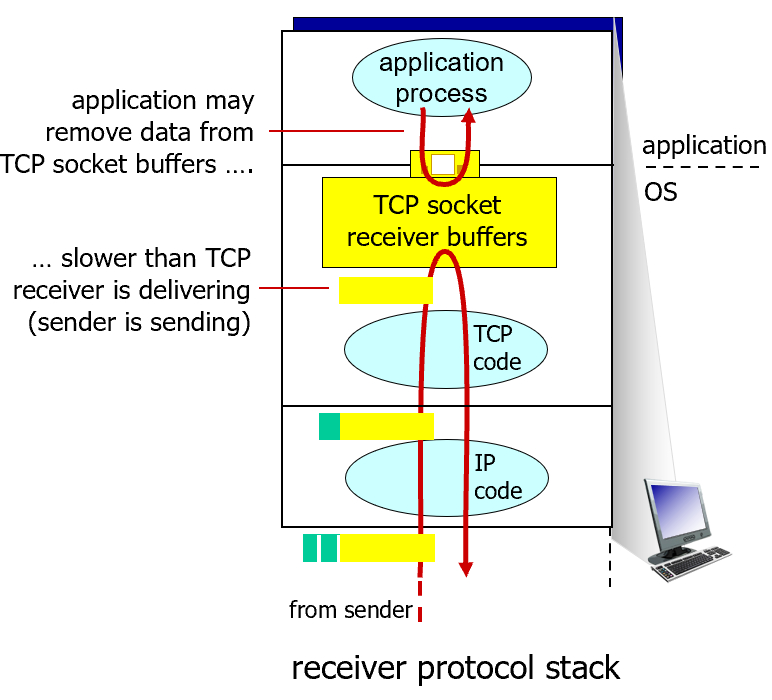
리시버가 감당할 수 있을 만큼만 센더가 데이터를 보내도록 조절하는 것
- TCP의 리시버는 수신 버퍼가 존재함.
- 근데 어플리케이션이 데이터를 읽는 속도가 버퍼에 도착하는 속도보다 느리면 버퍼가 꽉 차버릴 수도 있음
- 이때는 센더가 데이터를 계속 보내면 버퍼의 오버플로우 발생함.
TCP는 윈도우 기반 flow control을 사용한다.
리시버가 자신의 TCP 소켓 리시버 버퍼에 얼마나 빈 공간이 있는지를 ACK에 실어서 센더에게 알려줌
센더는 그 윈도우 사이즈 만큼만 데이터를 보낼 수 있음
만약 버퍼가 가득 차 버리면 센더는 일시적으로 전송을 멈춘다.
Connection Management
TCP는 데이터를 교환하기 전에 항상 호스트 간의 연결이 먼저 되어야 함.
연결을 설정하면서 서로 연결을 원한다는 것을 확인하고, 시퀀스 넘버, 버퍼 크기 등을 결정함.
2-way handshake
A가 B에게 요청
B가 OK
⇒ 둘 다 연결 상태 ESTAB
flaws
네트워크에는 딜레이, 손실, 재전송, 뒤바뀜이 있을 수 있다.
그래서 두 개의 메시지만으로는 reliability를 보장할 수 없음
특히 A는 B의 응답을 제대로 받았는지 확신하지 못함
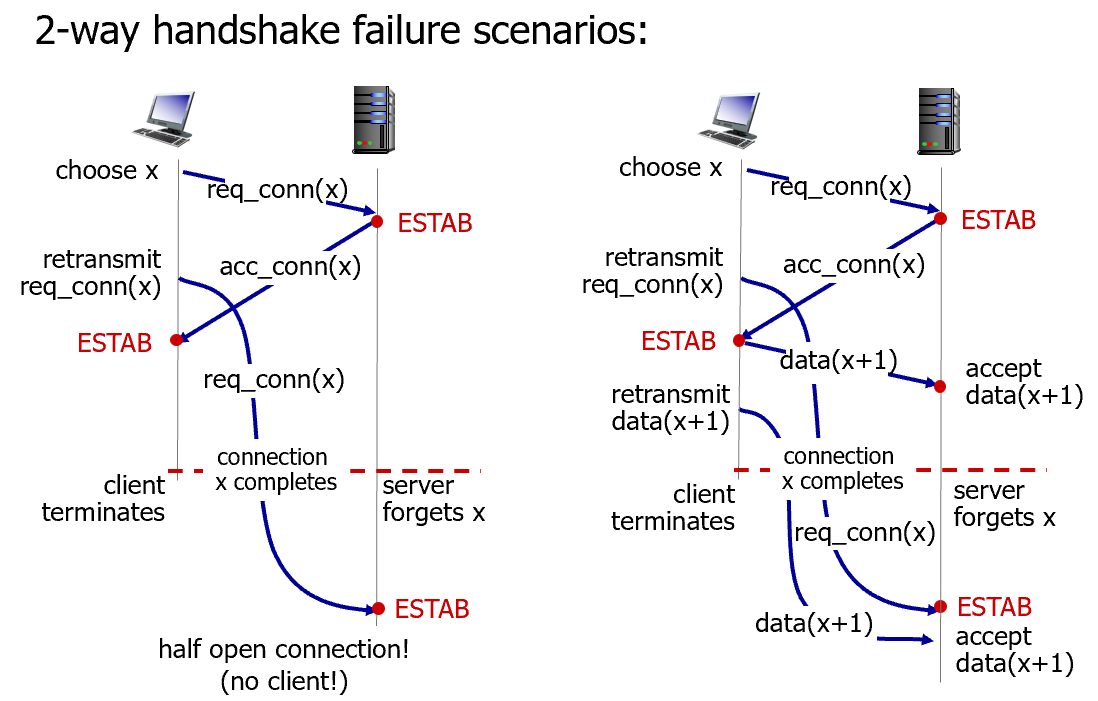
왼쪽 그림은 클라이언트가 서버에 연결 요청을 보내고 서버는 요청을 수락하고 ESTAB함. 수락했다는 신호를 다시 클라이언트로 보내는데 클라이언트는 기다리다 지쳐서 재전송함.
그 뒤에 클라이언트는 서버의 수락된 요청 신호를 받고 ESTAB함.
근데 이때 클라이언트가 연결을 포기하고 종료하면???????
클라이언트는 이미 연결을 종료했는데 서버는 이전에 두 번째로 보내진 요청을 새 연결로 착각해서 다시 ESTAB 상태가 되어버림.
반만 열린 연결 = half-open connection
3-way handshake
서로 살아 있고, 연결을 시작할 준비가 되어 있다는 것을 확인
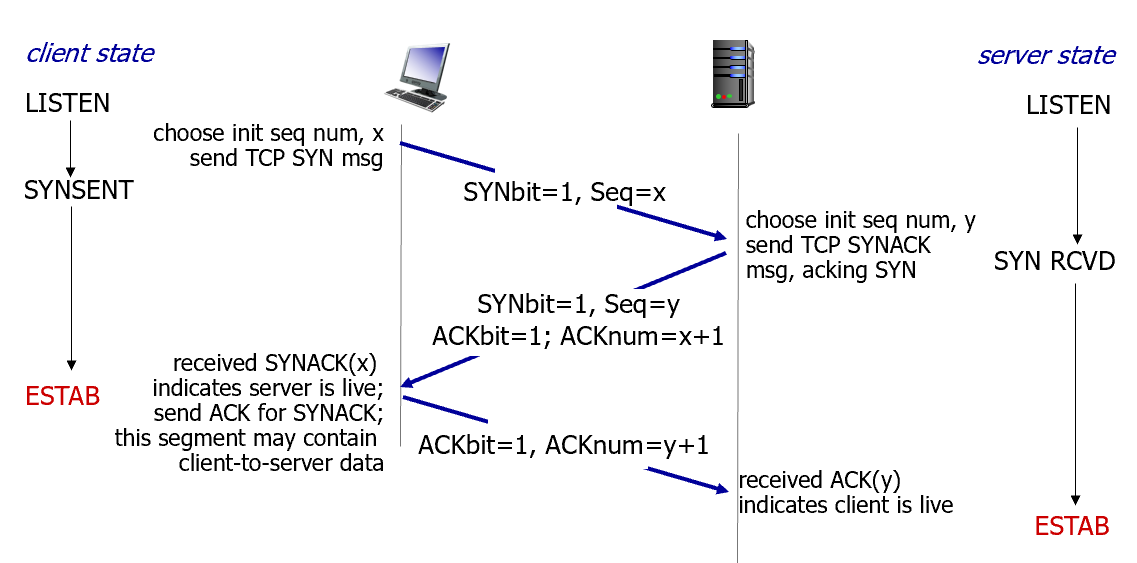
3단계로 이루어짐
- SYN
- SYN-ACK
- ACK
⇒ 시퀀스 번호까지 확인해서 Half-Open 문제를 해결함
closing a connection
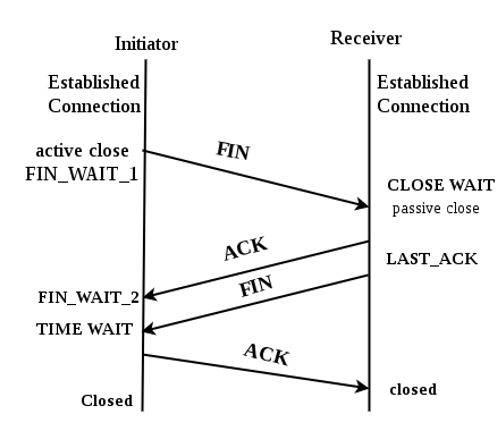
Congestion control
너무 많은 센더가 너무 많은 데이터를 너무 빨리 보내서 네트워크가 감당을 못하는 상황.
제어는 네트워크가 자체적으로 함.
혼잡의 징후로는 패킷 로스나 긴 딜레이가 있다.
네트워크가 감당 가능한 대역폭을 찾기 위해서 천천히 늘리고 문제가 생기면 확 줄이는 방식이 AIMD
- AI
- MD
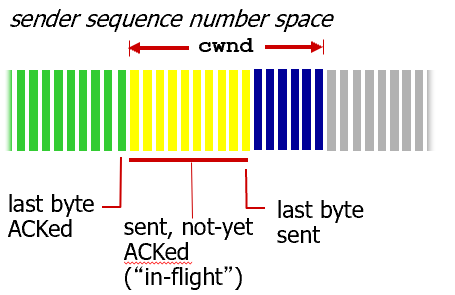

위에 식 알아두자
TCP Slow Start
네트워크 상태를 잘 모르니까 처음부터 막 보내면 혼잡이 생긴다.
그래서 천천히 조심스럽게 시작하고, 상태가 괜찮으면 빠르게 늘린다.
처음에 cwnd를 1mss로 시작
잘 받을 때마다 cwnd를 2배씩 증가 시킴.
초기 전송량은 느리지만 지수적으로 빨라지기 때문에 금방 빨라진다.
그래도 손실에 대한 대비책이 필요한데 두 가지가 있다.
TCP Tahoe
timeout 발생하면 cwnd를 1MSS로 초기화함
지수적으로 증가하다가 ssthresh에 도달하면 선형적으로 증가함.
3번 동일한 ACK을 받으면 이 녀석은 cwnd를 걍 1로 다시 초기화함.
그리고 다시 지수적으로… (반복)
TCP Reno
timeout 발생하면 cwnd를 1MSS로 초기화함
지수적으로 증가하다가 ssthresh에 도달하면 선형적으로 증가함.
3번 동일한 ACK을 받으면 이 녀석은 cwnd를 절반으로 세팅함.
그 뒤로는 선형적으로 증가.
그 뒤로 반복.
Fairness
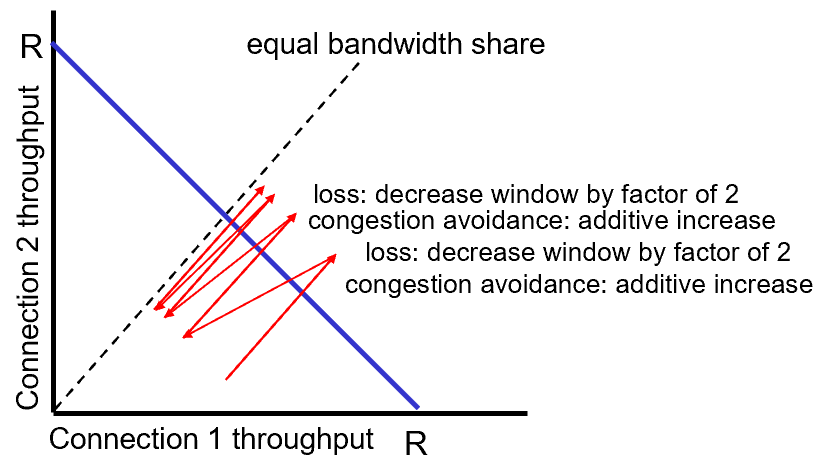
둘이서 TCP를 계속 돌리고 충돌이 날 수록 fair하게 bandwidth를 나눠가지게됨
⇒ Fair
근데 UDP는 congestion 이딴거 신경 안쓰고 걍 막 보내니까 TCP는 손해보는 입장임.
TCP는 congestion 상황을 인식하고 알아서 줄이는데, UDP는 안 그럼
Explicit Congestion Notification (ECN)
센더가 사고가 났을 때, window size 줄이는거 말고 congestion을 해결하는 방법
ECN은 TCP의 헤더 파일의 필드 이름.
IP 패킷의 헤더 파일에 어떤 판 필드가 2 bit로 정의되어있을 거임
type of service.
얘가 패킷을 보낼 때 라우터를 가는데 거기 버퍼가 꽉 차 있다면 내보내는 헤더필드의 ECN에 마크를 찍어줌.
원래는 ECN이 00 인데 중간 라우터에 오버헤드가 걸려 있다고 판단되면 11로 바꿔줌.
그러고 나서 리시버가 ACK을 보낼 때, ECE를 1을 마크해서 보내줌.
그러면 센더는 어느 라우터인지는 모르겠지만 가는 경로 중에 congestion이 있다는 것을 알 수 있다.
'지식 > 컴퓨터네트워크' 카테고리의 다른 글
| Network layer (0) | 2025.04.25 |
|---|---|
| Application layer (0) | 2025.04.25 |
| Introduction (2) | 2025.04.25 |


