Design Phase
Initial Phase
사용자의 데이터 요구사항을 파악하는 단계
- 무엇을 저장할지
- 누가 데이터를 사용할지
- 어떤 정보가 필요할지 파악
Second Phase
어떤 모델로 데이터를 표현할지 결정 (E-R 모델, 관계 모델)
- 선택한 데이터의 모델 개념을 적용함
- 요구 사항을 개념적 스키마로 작성
- 연산도 고려
여기서 도출되는게 개념적 설계
Final Phase
Logical Design
테이블, 속성, 키 등등 정의 시작
Physical Design
데이터의 실제 저장 구조를 정의한다.
Design Alternatives
데이터베이스 스키마를 설계할 때, 두 가지를 조심해야 함
- Redundancy: 같은정보를 여러 군데 반복해서 저장하는 것
- Incompleteness: 필요한 정보를 담을 수 없는 설계
Design Approaches
Entity-Relational Model
개념 설계, 구현 모델이랑은 독립적임.
Entity
다른 객체들과는 구별되는 구분 가능한 객체나 사람, 사물
거의 테이블이라고 생각할 수 있는데, 이 ER 개념 설계가 관계 모델로 변환할 때 테이블이 되는 건데, 변환 규칙을 고려해야됨.
결국 엔티티가 테이블이 되는거고, 엔티티는 ER 모델에서 존재하는 객체를 말하고 이걸 변환 규칙에 따라서 잘 변환하면 테이블이 되는 거임.
Relationship
여러 엔티티 사이의 연결 관계를 말한다
예를 들어서 Student 엔티티랑 Course 엔티티가 있다고 할 떄, 이 둘의 관계는 Student “takes” Course 라고 할 수도 있게.
보통 이 관계를 Action임
엔티티랑 관계 가지고 ERD를 만드는 겨
박스랑 다이아몬드로 모델을 그림으로 다이어그램 그린거
ER Model
ER model은 데이터베이스의 전체적인 논리적 구조를 표현하는 조직이나 시스템 전반에서 사용할 스키마를 디자인하기 위해 개발된 것이다.
아래 요소들의 조합으로 구성된다.
- Entity Sets
- Relation sets
- Attributes
Entity Sets
엔티티는 다른 객체들로부터 구별되어 존재하는 하나의 객체를 말한다.
예를 들어서 특정 인물이 될 수도 있고, 회사가 될 수도 있고,사건이 될 수도 있다.
엔티티 집합은 같은 속성을 가진 엔티티들의 집합이다.
예를 들어서 사람들의 모임, 동종업계 회사, 이런것들…
엔티티는 속성들의 집합으로 표현된다.
instructor = (ID, name, sslary)
course = (course_id, title, credits)
엔티티의 속성 중 일부가 주요키 역할을 할 텐데, 이는 각 엔티티 집합에서 각 엔티티를 고유하게 식별할 수 있게 해준다.

여기서 사각형 하나당 엔티티 집합을 의미한다.
내부에는 속성들의 리스트이다
언더라인은 주요키인 속성을 의미한다.
Relationship Sets
관계는 여러 엔티티 사이의 연결 상태를 의미한다.
위는 advisor라는 관계
관계 집합은 엔티티 집합으로부터 2개 이상의 엔티티가 참여한 것을 말한다.
관계 형성을 위해서는 엔티티가 2개 이다.
위의 그림을 더 해석해보면 하나의 관계 인스턴스 이며, 이런 애들이 모여서 관계 집합을 만든다.
여기서 어드바이저는 관계 집합
관계 집합은 ER 다이어그럄에서 다이아몬드로 표시함
속성이 관계 집합에 끼어들 수 있음
이렇게 하면 관계 집합 어드바이저는 date 속성을 가지게 된다.
Roles
하나의 엔티티 집합이 같은 관계 안에서 두 번 등장할 수 있음
이렇게 하나의 엔티티 집합이 한 관계 안에서 두 번 등장하면 Role을 정해주어야함.
여기서는 코스 아이디랑 프리큐 아이디 이렇게 정해줫음.
Degree of a Relationship Set
관계 집합의 차수는 해당 관계 집합에 참여한 엔티티 집합의 수다.
두 개의 엔티티 집합이 참여했으면 Binary Relationship이라고 한다.
세 개의 엔티티 집합이 참여했으면 Ternary Relationship이라고 한다.
Non-binary Relationship Sets
대부분은 그냥 바이너리 관계 집합이이잠 가끔씩 터네리가 나옴
“어떤 학생이 어떤 프로젝트에서 어떤 교수의 지도를 받는다”
“어떤 학생과 여떤 교수가 함께 프로젝트를 한다”
…
역할을 지정하지 않아서 다양한 의미로 해석이 가능함.
Complex Attributes
Simple
더 이상 쪼개지지 않는 속성
Composite
여러 개의 구성요소로 나뉘는 속성
Single-Valued
하나의 값만 가지는 속성
Multivalued Attributes
여러 개의 값을 가질 수 있는 속성
Derived Attributes
다른 속성으로부터 계산 가능한 속성
저장되지 않고, 필요할 때 계산됨.
예를 들어서 생일이 저장되어있으면 나이 속성은 파생 속성으로 따로 저장하지 않고 생일로부터 계산한다.
Domain
각 속성이 가질 수 있는 값들의 범위
예를 들어서 age는 정수, 성별은 M 아니면 F, 이메일은 문자열이면서 @를 포함하도록…

ID는 심플이면서 싱글
name은 컴포짓
first_name 은 심플이면서 싱글
middle_initial 은 심플이면서 싱글
ast_name은 심플이면서 싱글
address는 컴포짓
street도 컴포짓
street_number는 심플이면서 싱글
street_name은 심플이면서 싱글
apt_number는 심플이면서 싱글
city는 심플이면서 싱글
state는 심플이면서 싱글
zip은 심플이면서 싱글
phone_number는 심플이면서 멀티 벨류
date_of_birtth는 심플이면서 싱글
age() 는 파생
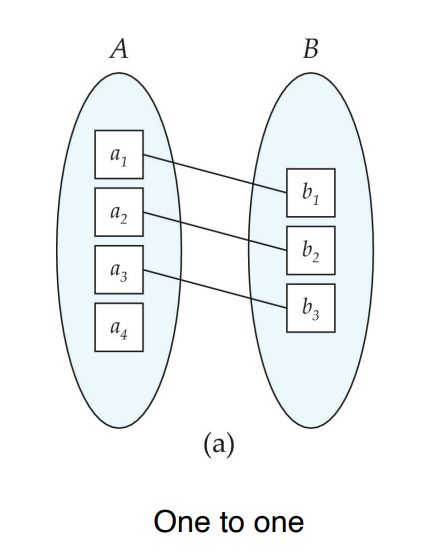
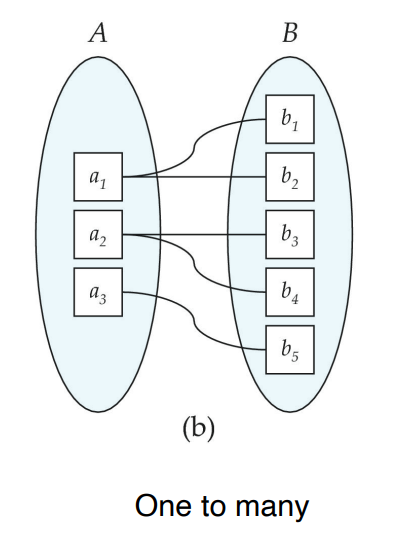
Mapping Cardinality Constraints
One to One
One to Many
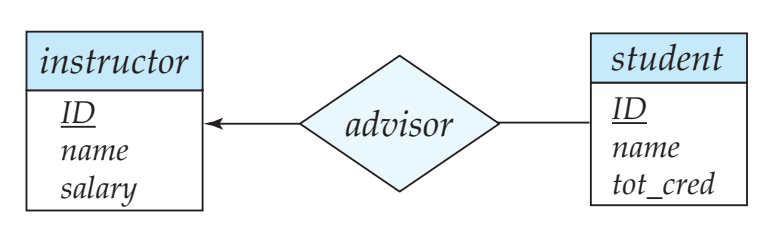
Many to One
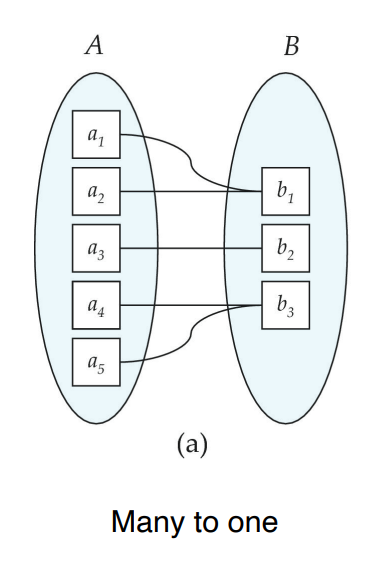
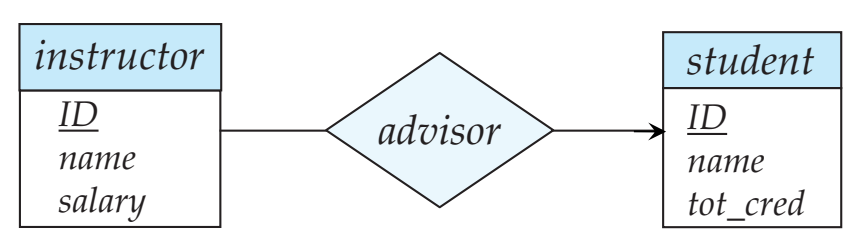
Many to Many
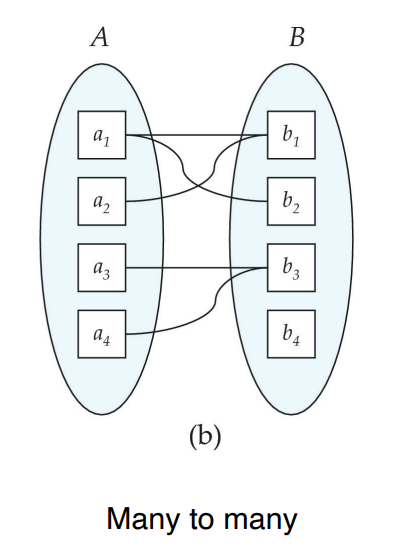
Total and Partial Participation
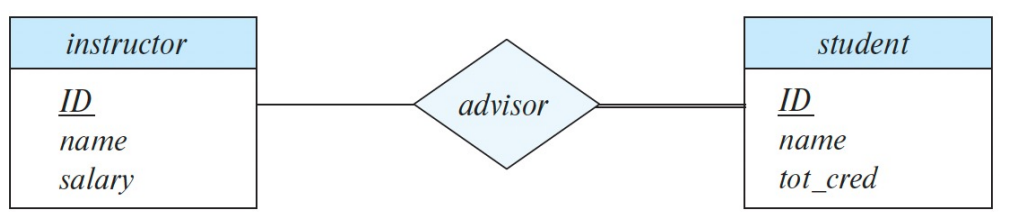
토탈
모든 엔티티 인스턴스가 최소 하나의 관계에 참여해야 함
굵은 더블 라인
모든 학생은 담당 교수가 있어야 함
파샬
일부 엔티티 인스턴스는 관계에 참여하지 않아도 됨
일반 실선
교수들은 담당 학생이 없을 수도 있음
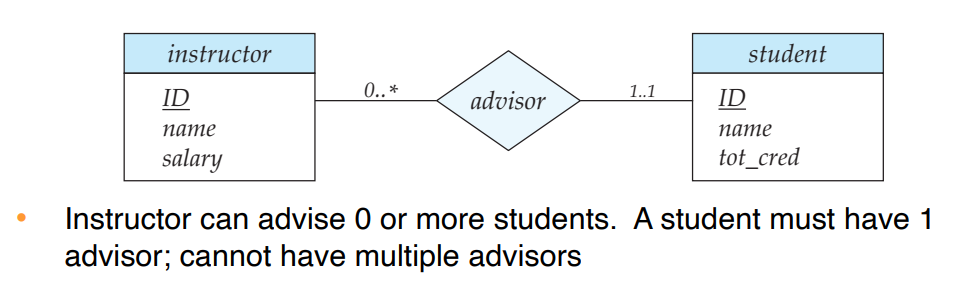
Notation for Expressing More Complex Constraints
복잡한 제약 조건을 숫자 범위로 표현 가능
인스턴스가 관계에 참여할 수 있는 최소/최대 개수를 l..h 형태로 나타낸다.
l : 최소 참여 개수
h : 최대 참여 개
위 사진은 아래 사진과 같은 의미
Cardinality Constraints on Ternary Relationship
터네리 관계에서는 한 엔티티 집합 쪽에서만 화살표를 하나만 사용할 수 있음
그 화살표는 해당 방향으로 유일임을 의미한다.
화살표가 하나면 유일성이 보장된다.
만약에 화살표가 인스트럭으 방향에 있으면 (student, project) 는 하나의 인스트럭트와만 연결됨.
Primary Key
Entity set
엔티티 집합에서 주요키는 엔티티를 고유하게 식별하게 해주는 키
Relationship set
관계 인스턴스를 구분하기 위한 키
보통 관계에 참여하는 엔티티들의 주요키의 조합이 주요키가됨
Weak Entity set
자체적으로는 주요키가 없음
관계된 강한 엔티티의 기본키 + 자신의 구분자를 합쳐서 구별한다.
Primary key for Entity Sets
정의 상으로 각각의 엔티티들은 엔티티 집합 내에서 구별 가능해야 함.
모든 엔티티는 고유해야 한다는 것.
그래서 개체가 다르다는 것은 속성의 값이 달라야 함.
여기서 이 속성값들은 엔티티들을 유일하게 식별할 수 있게 해주어야함.
이 속성들의 집합이 Primary key이다.
Primary Key for Relationship Sets
관계도 엔티티 처럼 중복 없이 구분가능해야 함
그래서 관계에서도 Primary Key를 정해야되는데, 관계에서는 관계에 참여한 엔티티들의 Primary Key 집합으로 함.
이 주요키를 정하는 기준은 매핑 카디널리티 제약조건을 따르는 방식으로 함.
Weak Entity Sets
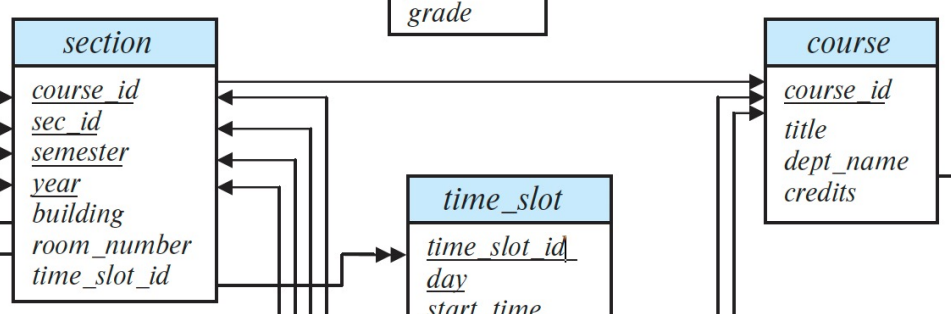
(섹션이랑 코스만 보셈, 릴레이션 스키마인)
섹션 엔티티가 위에 밑 줄 친 애들에 의해서 유일하게 식별된다고 하자.
섹션이 코스 아이디를 식별자의 일부로 포함하고 있음.
그래서 섹션은 어떤 코스에 속해 있어야지만 구별이 됨.
그러면 섹션과 코스는 관계를 만들 수 있는데, 관계를 만들고 봤더니 코스 아이디 속성이 중복됨. (redundant) 이거 안좋음.
섹션은 코스가 없으면 같이 없어지는 존재인데, 색션이 코스 아이디를 가지면서 독립적으로 존재하면 이 종속의 의미를 부여했다고 보기 어려움.
(독립적인 존재를 스트롱 엔티티라고 함)
그래서 Weak Entity Sets라는 개념을 도입.
섹션은 코스 없이는 살지 못하는 약한 개체
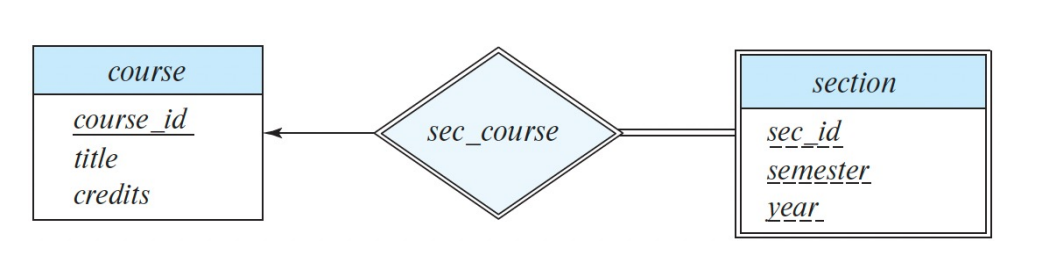
- 약한 개체는 더블 렉탱글
- 식별자들은 대쉬 라인
- 관계는 더블 디아몬드
- 관계와 약한 개체 사이는 더블 라인
Reduction to Relation Schemas
엔티티 집합이랑 관계 집합은 결국 관계 스크마로 바꿀 수 있음.
엔티티 집합은 각각 테이블 하나로, 관계 집합은 경우에 따라서 외래키 아니면 테이블로 바뀜.
모든 정보는 결국 테이블로 구성된 관계 스키마가 될 수 있음
Representing Entity Sets
강한 개체는 바뀔 때 걍 그대로 바뀜

근데 약한 개체는 식별자에 관계를 맺은 강한 개체의 식별자를 포함해야함.
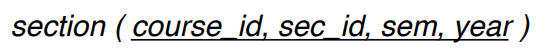
Composite Attributes
걍 플래튼!
name
first_name
middle_name
last_name⇒
first_name
middle_name
last_nameMultivalued Attributes
멀티 벨류 가지는 속성들은 따로 테이블을 만들어 줘야됨

instructor(ID, name, ...)
inst_phone(ID, phone_number)(22222, 456-7890)
(22222, 123-4567)관계형 모델은 한 속성에 여러 값을 넣을 수 없음.
그래서 무조건 정규화해서 분리해야됨.
Redundancy of Schemas
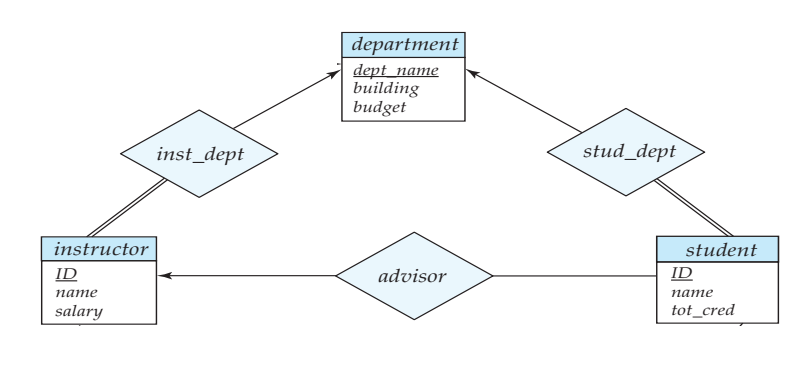
일대다, 다대일 관계에서는 ERD를 관계 스키마로 표현할 때, 관계 집합을 별도의 테이블로 만들지 않고 다수 쪽 테이블에 외래 키를 추가하는 방식으로 표현할 수 있음.
(다수 쪽이 토탈이어야하는 조건 추가)
❌
┌─────────────┐ ┌──────────────┐ ┌─────────────┐
│ department │ │ inst_dept │ │ instructor │
│ dept_name(PK)◄─────────│ dept_name(FK)│─────────►│ ID (PK) │
│ building │ │ i_id (FK) │ │ name │
│ budget │ └──────────────┘ │ salary │
└─────────────┘ └─────────────┘⭕
┌─────────────┐ ┌────────────────────────────┐
│ department │ │ instructor │
│ dept_name │◄──────────│ ID │
│ building │ FK │ name │
│ budget │ │ salary │
└─────────────┘ │ dept_name (FK to dept) │
└────────────────────────────┘
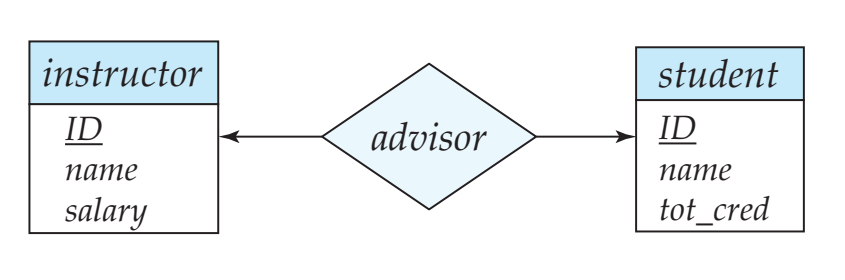
One-to-One 관계에서의 스키마 중복
일대일 관계에서 두 개체 중 어느 쪽의 외래 키를 추가해도 되니까 관계 테이블을 생략하고 속성으로 걍 써주면 됨
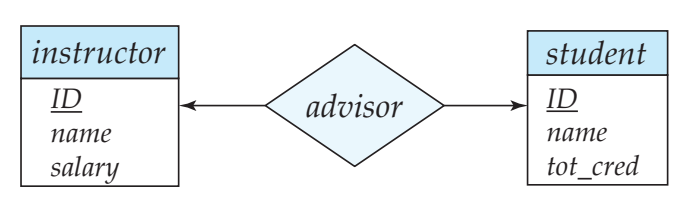
-- 방식 1: student 테이블에 FK 추가
student(ID, name, tot_cred, advisor_id) -- FK → instructor.ID
-- 방식 2: instructor 테이블에 FK 추가
instructor(ID, name, salary, student_id) -- FK → student.IDWeak Entity 관계에서의 스키마 중복
약한 개체는 관계된 강한 개체의 주요키를 자체적으로 포함하기 때문에 굳이 관계 집합을 다시 테이블로 만들 필요가 없음. 만들면 중복임.
Specialization
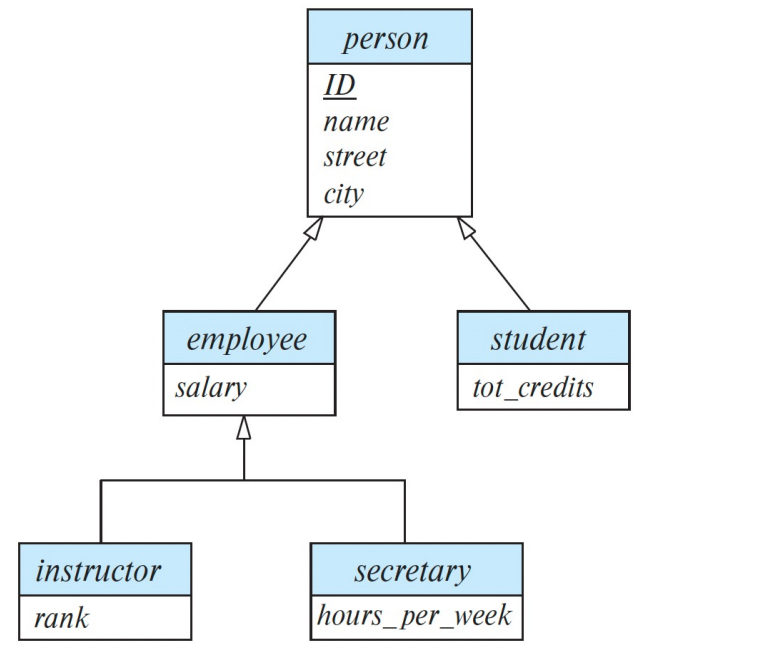
탑 다운 방식
전체 엔티티 집합에 따라서 하위 집합을 결정한다.
지금 그림에서는 사람이라는 상위 엔티티 집합 아래에 직원이랑 학생이라는 하위 엔티티 집합이 존재하는걸 볼 수 있다.
하위 엔티티는 상위 엔티티의 속성이랑 관계를 모두 물려받음
- Overlapping: 위 그림에서 employee와 student는 겹칠 수 있음
- Disjoint: 위 그림에서 instructor 와 secretary 는 겹칠 수 없음.
Representing Specialization via Schemas
Method1

걍 상속 관계 생각해서 주요키만 하위 엔티티 집합에 넘겨줌.
그러면 중복을 최소화 할 수 있음.
그래서 person 에 해당하는 정보를 얻기 위해서는 다른 테이블과 join 을 해야 함.
근데 employee는 두 번 조인해야겠지 lower 이랑 higher .
근데 테이블 크기가 커지면 join이 부담스럽고 비쌀 수 있음…
Method2

이전에는 주요키만 넘겨주는 식이었는데 이번에는 걍 모든 속성 다 넘겨주기.
이러면 join 연산을 할 필요가 없어지고 빠름.
근데 저장 공간이 많이 필요할거임.
여기서도 Disjoint, Overlapping 똑같이 적용됨.
Generalization
바텀 업 방식
여러개의 하위 엔티티에서부터 공통 속성을 추출해서 상위 엔티티 집합으로 만드는 과정
Specialization이랑 inverse 관계라 하나만 잘 알아두면 됨
(Specialization인지 Generalization인지 사실 ERD만 보고는 구별이 안됨. 걍 해석하는 사람의 마음으로 구별하는 것)
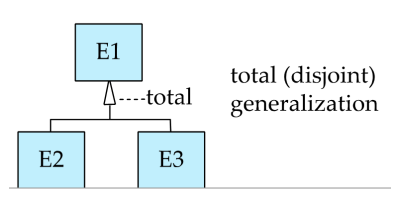
Completeness constraint
- Total: 상위 엔티티의 모든 인스턴스들이 반드시 하위 엔티티 중에 하나에 속해야 함. (이중선으로 표현)
- Partial: 상위 엔티티가 반드시 하위 엔티티 중에 하나에 속할 필요는 없음. (단일선으로 표현)
ERD를 표현할 때, 디폴트로 partial generalization 임. (아무것도 안써주면 걍 이거임)
그래서 total 을 표현할 때는 에로우에 대쉬드 라인 옆으로 끌어놓고 total이라고 써줘야 함.
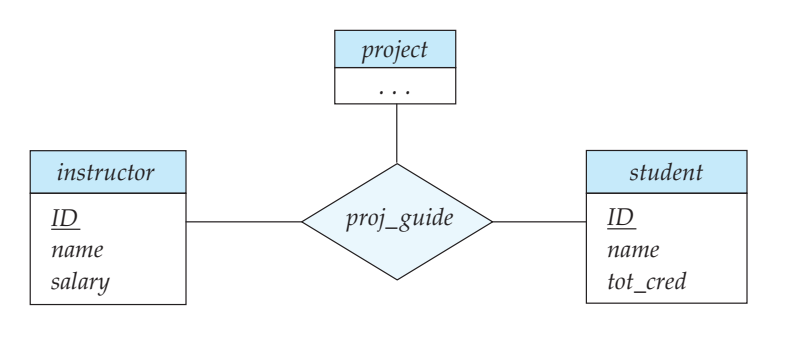
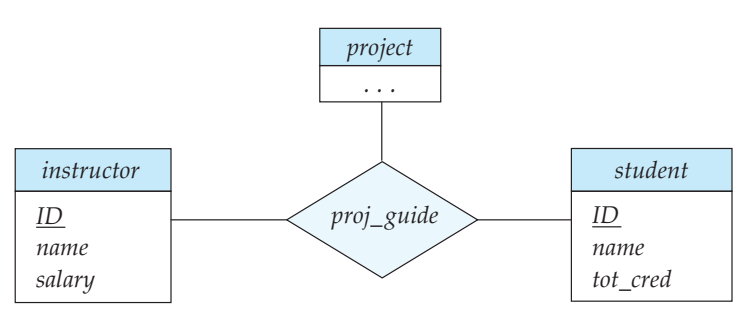
Aggregation
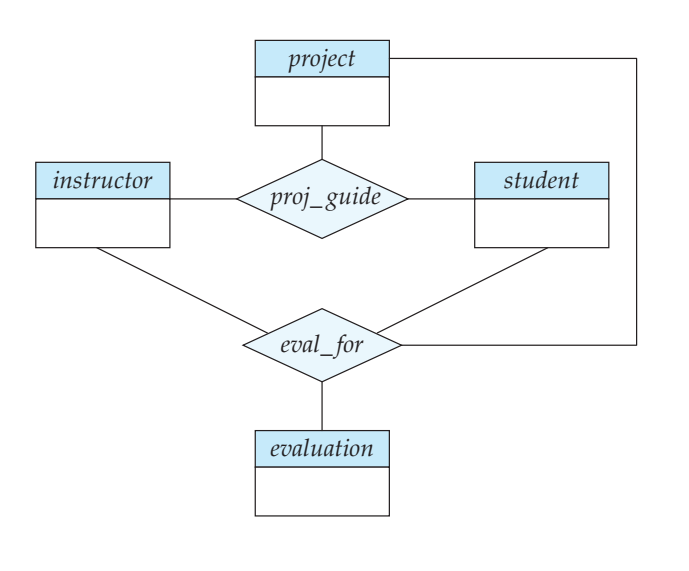
여기서 proj_guide 는 ternary relationship 임.
“어떤 교수가 어떤 학생의 프로젝트를 지도한다”
내가 원하는 설계는 proj_guide 를 기반으로 evaluation하는 것임.
그래서 evaluation은 studnet, instructor, project 에 의해서 이루어짐
그래서 위처럼 연결을 했더니 문제가 생김
나는proj_guide를 기반으로 평가를 해야되는데 관계 해석에 대한 오해가 생김정보의 중복 문제가 발생함.
ER 모델은 관계들의 관계를 표현하기가 어렵다는 점이 문제임.
어떤 교수가 학생을 프로젝트에서 지도하고(ternary relation) 이를 평가한다고 가정하자.
그래서 evaluation이라는 하나의 엔티티를 모델링하고 주요키로는 evaluation_id 를 가진다고 하자.
그러면 이제 프로젝트에 대한 평가를 하기 위해서 하나의 방법으로 instuctor, student, project, evalutaion 간의 4항 관계로 eval_for 를 만들었다고 해보자.
평가를 하기 위해서는 4항 관계가 반드시 필요하다.
왜냐하면 insturctor, project, student 중에서 하나라도 빠지면 어떤 교수의 평가인지?
어떤 프로젝트르 평가한건지? 어떤 학생의 평가인지?에 대한 의문이 생길 수 밖에 없기 때문이다.
이렇게 설계해서 아래와 같은 ER 모델을 얻었다고 하자
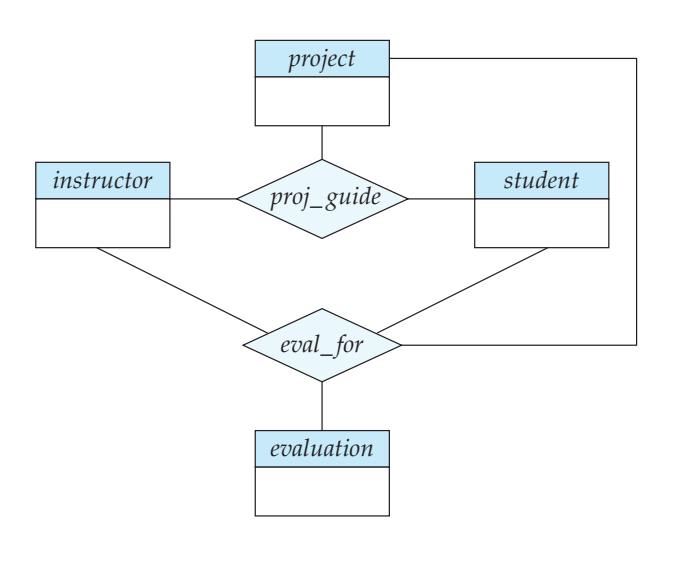
그냥 딱 보기에는 proj_guide 에 관계된 엔티티들이 eval_for 에도 관계되어 있으니까 두 관계를 하나로 그냥 퉁칠 수 있겠다고 생각할 수도 있다. (proj_guide를 제거하고 eval_for만 사용하는 방식처럼)
근데 이렇게 하면 안됨.
왜냐하면 어떤 (instructor, student, project)는 아직 평가가 이루어지지 않았을 수도 있기 때문이다.
proj_guide 는 모든 지도 관계, eval_for 은 그 중에서 평가가 있는 것들만 나타내니까!!
그래서 제거는 못하는데 정보 중복 문제도 있음.
eval_for에 있는 정보들은 proj_guide에도 있기 때문임.
이걸 테이블로 만든다?? → 데이터 중복이 엄청날거임
그럼 그냥 evaluation을 엔티티가 아니라 속성으로 모델링하면 안될까??
proj_guide 에 속성으로 걍 넣어놓으면 안되냐는 것
근데 이것도 다른 엔티티랑 연결해서 관계 만든다고 생각하면 그때부터는 머리가 띵 해지는거임.
evaluation 엔티티로 장학금 준다고 가정하면 행정 처리하는 사람이랑 evaluation 이랑 관계를 만들어야 되는데, 이러면 나중에 다시 엔티티로 분리하기 는 너무 짜증날거임.
그러면 다시 데이터 중복 문제도 수면 위로 올라오고…
어쨋든 evaluation 을 속성으로 바꾸는 것도 좋은 방법은 아님..
그래서 Aggregation!!!!!!!!!!!!!!!!!!!!
현재 proj_guide는 eval_for보다 상위 관계임.
이 상위 관계를 하나의 엔티티 집합이라고 간주하는거임.
이렇게 하면 일반적인 엔티티랑 똑같이 다룰 수 있음.
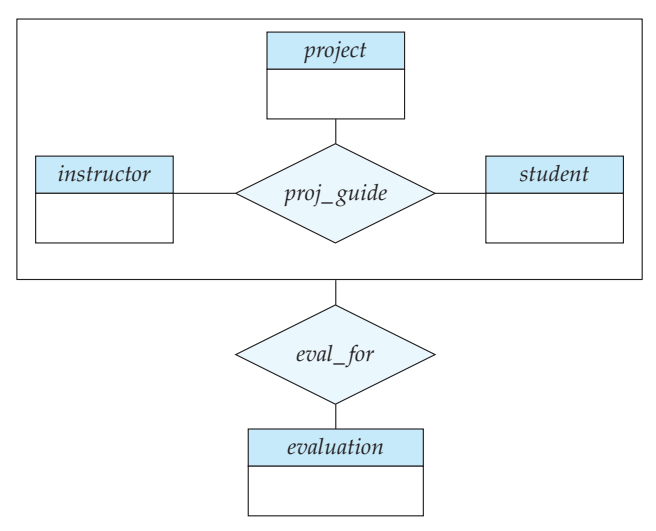
Reduction to Relational Schemas
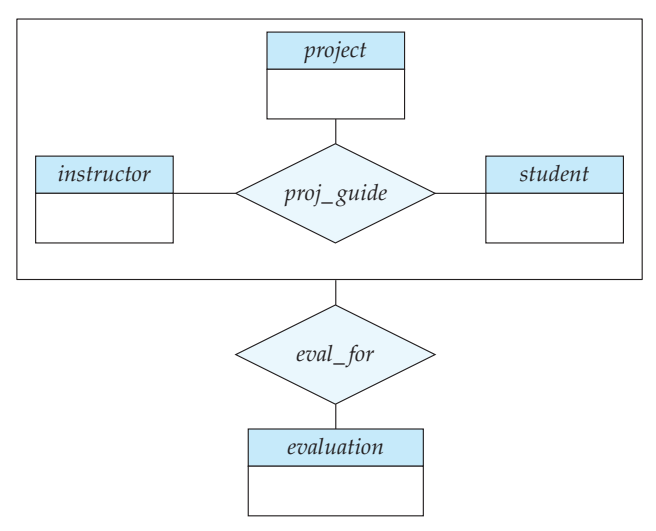
이걸 관계형 모델로 표현하려면 하나의 테이블을 만들어야하고 그 테이블에는 아래 항목들이 포함되어야한다
- agrregation된 관계의 주요키들
- 연결된 엔티티의 주요키들
- 연관된 엔티티의 다른 속성들
그리고 proj_guide 를 엔티티처럼 다룬다고 했는데 관계형 모델에선 그걸 위한 별도 테이블을 만들 필요는 없음
이미 eval_for 테이블에 그 키들이 다 들어 있어서.
'지식 > 데이터베이스시스템' 카테고리의 다른 글
| Intro to Relational Model (0) | 2025.03.29 |
|---|
